1. Comprendre les groupes de disponibilité Always On
1.1 Qu'est-ce que c'est et comment ça fonctionne
Les groupes de disponibilité Always On (AG) sont un SQL Server Entreprise la haute disponibilité et une solution de reprise après sinistre fonctionnant au niveau de la base de données. Un groupe de disponibilité regroupe une ou plusieurs bases de données utilisateur au sein d'une unité de basculement unique et les réplique sur un maximum de huit répliques secondaires grâce à la réplication continue des journaux de transactions. En cas de défaillance de la réplique principale, une réplique secondaire synchrone désignée prend automatiquement le relais, rétablissant l'accès en quelques secondes sans stockage partagé ni intervention manuelle.
1.2 Groupes de disponibilité Always On vs. Instances de cluster de basculement
SQL Server Always On comprend deux technologies distinctes : les groupes de disponibilité (AG) et les instances de cluster de basculement (FCI) :
| Groupes de disponibilité toujours activés | Instances de cluster de basculement Always On | |
|---|---|---|
| Portée du basculement | Niveau de la base de données | Au niveau de l'instance (toutes les bases de données basculent simultanément) |
| Réplication de données | Réplication basée sur les journaux vers chaque secondaire | Aucun — tous les nœuds partagent le même espace de stockage |
| Stockage partagé | Pas nécessaire | Requis (réseau de stockage (SAN), iSCSI, S2D ou SMB) |
| Secondaires lisibles | Oui | Non |
| Reprise après sinistre | Intégré (répliques asynchrones entre les sites) | Non intégré sans couplage avec AG |
Quand utiliser chacun d'eux : Utilisez FCI lorsque vous avez besoin d'un basculement au niveau de l'instance et que vous disposez déjà d'une infrastructure de stockage partagée. Utilisez AG lorsque vous avez besoin d'une granularité au niveau de la base de données, de disques secondaires lisibles ou d'une reprise après sinistre.ost Pour une protection complète, combinez les deux : exécutez chaque réplique en tant que nœud FCI et reliez-les dans un AG.
1.3 Avantages et limitations
Avantages:
- Basculement automatique avec un objectif de temps de récupération (RTO) quasi nul pour les répliques synchrones ;
- aucune perte de données (objectif de point de récupération (RPO) = 0) en mode de validation synchrone ;
- aucun stockage partagé requis — chaque réplique utilise un stockage local indépendant ;
- Les serveurs secondaires lisibles déchargent les charges de travail de reporting et de sauvegarde du serveur principal ;
- prend en charge à la fois la haute disponibilité locale (HA) et la reprise après sinistre intersites (DR) au sein d'une seule configuration.
Limitations:
- Nécessite le clustering de basculement Windows Server sur toutes les répliques ;
- Édition Entreprise pour un ensemble complet de fonctionnalités (l'édition Standard prend en charge Basic AG avec des restrictions importantes) ;
- Le mode de validation synchrone ajoute une latence aux opérations d'écriture proportionnelle au temps d'aller-retour du réseau ;
- Les connexions, les tâches de l'Agent SQL et les serveurs liés ne sont pas synchronisés automatiquement dans SQL Server 2019 et avant (résolu en SQL Server 2022 contenait des groupes de disponibilité).
2. Architecture des groupes de disponibilité Always On
2.1 Composantes et concepts fondamentaux
2.1.1 Bases de données de disponibilité
Les bases de données de disponibilité sont les bases de données utilisateur participant à un groupe de disponibilité. Ces bases de données doivent répondre à des exigences spécifiques : elles doivent utiliser le modèle de récupération complète, disposer d’une sauvegarde complète et exister sur le réplica principal avant d’être ajoutées à un groupe de disponibilité.
Lorsqu'une base de données rejoint un groupe de disponibilité, elle fait partie d'un ensemble synchronisé qui bascule de manière unifiée. Toutes les bases de données d'un même groupe partagent le même état de basculement : si le réplica principal tombe en panne, toutes les bases de données basculent simultanément vers le même réplica secondaire. Ceci garantit la cohérence des applications qui s'appuient sur plusieurs bases de données liées.
2.1.2 Disponibilité des répliques
Les répliques disponibles sont SQL Server des cas où host Des copies des bases de données de disponibilité. Chaque réplique conserve sa propre copie physique des bases de données, synchronisée par la réplication des enregistrements du journal des transactions. Un groupe de disponibilité peut contenir jusqu'à neuf répliques : une réplique principale et jusqu'à huit répliques secondaires.
2.1.3 Réplique principale
La réplique principale hostIl s'agit de la copie en lecture-écriture des bases de données de disponibilité. Toutes les modifications de données (INSERT, UPDATE, DELETE) sont effectuées sur le réplica principal. Les applications clientes se connectent au réplica principal pour toutes les opérations d'écriture et, par défaut, également pour les opérations de lecture.
2.1.4 Répliques secondaires
Répliques secondaires host Des copies en lecture seule des bases de données de disponibilité sont mises à jour par l'application continue des enregistrements du journal des transactions reçus du réplica principal. Chaque réplica secondaire reçoit, renforce et applique ces enregistrements afin de maintenir la synchronisation de ses copies de base de données avec le réplica principal.

2.2 Modes de disponibilité
2.2.1 Mode de validation synchrone
Le mode de validation synchrone garantit une protection contre la perte de données en exigeant que le réplica principal attende la confirmation de la validation des enregistrements du journal des transactions sur le réplica secondaire avant de valider les transactions. Ce mode est essentiel pour les configurations à haute disponibilité où toute perte de données est inacceptable.
2.2.2 Mode de validation asynchrone
Le mode de validation asynchrone privilégie les performances du réplica principal en autorisant la validation des transactions sans attendre la confirmation du renforcement du journal par les réplicas secondaires. Ce mode est adapté aux réplicas de reprise après sinistre ou lorsque la latence réseau rend la validation synchrone impraticable.
Le compromis réside dans le risque de perte de données lors d'un basculement. Si le réplica principal tombe en panne, certaines transactions validées pourraient ne pas avoir atteint le réplica secondaire. L'ampleur de cette perte dépend de la bande passante du réseau, des performances du réplica secondaire et du moment de la panne. Les entreprises doivent accepter ce risque lorsqu'elles utilisent le mode asynchrone.

2.3 Types de basculement
2.3.1 Basculement automatique
Le basculement automatique permet au groupe de disponibilité de détecter une défaillance du réplica principal et de promouvoir automatiquement un réplica secondaire en réplica principal, sans intervention de l'administrateur. Cette fonctionnalité minimise le RTO en éliminant la nécessité d'une réponse manuelle aux pannes.
Le basculement automatique nécessite le mode de validation synchrone pour garantir l'absence de perte de données. Lorsqu'il est activé, le groupe de disponibilité surveille en permanence l'état du réplica principal. Si ce dernier ne répond plus ou tombe en panne, le cluster de basculement Windows Server déclenche automatiquement un basculement vers un réplica secondaire désigné.
2.3.2 Basculement manuel
Le basculement manuel permet aux administrateurs de transférer intentionnellement le rôle de réplica principal vers un réplica secondaire, généralement à des fins de maintenance planifiée ou de test. Contrairement au basculement automatique, le basculement manuel nécessite une intervention explicite de l'administrateur.
Le basculement manuel sans perte de données est disponible pour les réplicas à validation synchrone. L'administrateur initie le basculement via SQL Server Management Studio, Transact-SQL ou PowerShell. Le réplica principal termine le traitement des transactions en cours et envoie tous les enregistrements de journal restants au tarIl obtient le rôle secondaire et attend la confirmation avant de transférer le rôle principal.
Le basculement manuel est également possible avec les réplicas à validation asynchrone, mais il nécessite un basculement forcé avec un risque de perte de données. Les administrateurs ne doivent recourir au basculement manuel forcé qu'en cas de sinistre avéré, lorsque le réplica principal est indisponible et que la perte de données est acceptable par rapport à une interruption de service prolongée.
2.3.3 Basculement forcé
Le basculement forcé permet de basculer vers une réplique secondaire asynchrone ou vers une réplique secondaire non entièrement synchronisée, en reconnaissant explicitement le risque de perte de données. Cette option est utilisée en dernier recours lorsque la réplique principale est indisponible et qu'aucune réplique secondaire synchronisée n'est disponible.

2.4 Synchronisation des données
2.4.1 Fonctionnement de la synchronisation des données
La synchronisation des données dans les groupes de disponibilité Always On s'effectue par la transmission continue des enregistrements du journal des transactions du réplica principal vers tous les réplicas secondaires. Cette synchronisation basée sur le journal garantit la cohérence des données tout en permettant un stockage indépendant pour chaque réplica.
2.4.2 Enregistrements du journal des transactions et renforcement de la sécurité
Le renforcement des journaux de transactions est une étape cruciale : les enregistrements de journal sont écrits sur un support de stockage durable, au niveau des répliques secondaires. Ce renforcement garantit la pérennité des enregistrements en cas de défaillance des répliques secondaires et leur relecture lors de la récupération.

2.5 Échelle de lecture et répliques secondaires lisibles
2.5.1 Déchargement des charges de travail en lecture seule
Les répliques secondaires lisibles permettent aux organisations de décharger la réplique principale des charges de travail intensives en lecture, améliorant ainsi les performances globales du système et l'utilisation des ressources. Cette capacité d'adaptation à la charge de lecture est l'un des principaux avantages des groupes de disponibilité par rapport aux solutions de haute disponibilité plus anciennes.
Lors de la conception des configurations de groupes de disponibilité, les organisations doivent tenir compte des exigences de charge de travail en lecture seule. Plusieurs serveurs secondaires en lecture seule permettent de répartir la charge de reporting sur plusieurs serveurs. Les listes de routage en lecture seule définissent l'ordre de réception des connexions en lecture par les serveurs secondaires, ce qui permet de mettre en œuvre des stratégies d'équilibrage de charge.
2.5.2 Opérations de sauvegarde sur les réplicas secondaires
L'exécution des sauvegardes sur des répliques secondaires réduit la charge d'entrée/sortie (E/S) et de processeur (CPU) sur la réplique principale, lui permettant ainsi de se concentrer sur les charges de travail transactionnelles. Cette fonctionnalité aide les entreprises à répondre aux exigences de sauvegarde sans impacter les performances de production.
SQL Server Ce système prend en charge les sauvegardes complètes de bases de données, les sauvegardes différentielles et les sauvegardes des journaux de transactions sur les réplicas secondaires. Les préférences de sauvegarde peuvent être configurées pour privilégier les réplicas secondaires, le réplica principal, uniquement les réplicas secondaires ou n'importe quel réplica. Le système de sauvegarde sélectionne automatiquement le réplica approprié en fonction de ces préférences et de sa disponibilité.
Pour plus de détails sur SQL Server sauvegarde, consultez notre guide complet.

2.6 Écouteurs de groupe de disponibilité
2.6.1 Qu'est-ce qu'un auditeur ?
Un écouteur de groupe de disponibilité est un nom de réseau virtuel (VNN) et une adresse IP utilisés par les applications clientes pour se connecter aux bases de données du groupe de disponibilité. L'écouteur redirige automatiquement les connexions vers le réplica principal actuel, évitant ainsi aux applications de devoir identifier le serveur principal.
2.6.2 Routage des connexions client
Le routage des connexions client via l'écouteur prend en charge les intentions de connexion en lecture-écriture et en lecture seule. L'écouteur examine la requête de connexion et la route vers le réplica approprié en fonction de l'intention de l'application.

3. Prérequis et exigences
3.1 Clustering de basculement Windows Server pour les groupes de disponibilité
3.1.1 Principes fondamentaux du clustering de basculement Windows Server
Le clustering de basculement Windows Server (WSFC) constitue la base des groupes de disponibilité Always On en gérant l'appartenance au cluster, la surveillance de l'état et l'orchestration du basculement. Contrairement aux instances de cluster de basculement, les groupes de disponibilité utilisent WSFC uniquement pour la coordination du cluster, et non pour la gestion du stockage partagé.
Chaque projet récompensé par un SQL Server Toute instance participant à un groupe de disponibilité doit être un nœud d'un cluster WSFC. Ce cluster gère le vote du quorum, la détection de l'état des nœuds et l'état des ressources du groupe de disponibilité. En cas de défaillance du réplica principal, WSFC coordonne le basculement et met à jour les ressources du cluster pour refléter le nouveau réplica principal.

3.1.2 Configuration du quorum du cluster
Le quorum du cluster détermine quels nœuds peuvent fonctionner en cas de problèmes de connectivité réseau, évitant ainsi les situations de « split-brain » où plusieurs nœuds prétendent indépendamment être primaires. La configuration du quorum définit ce qui constitue un vote majoritaire pour les décisions du cluster.
Plusieurs modes de quorum sont disponibles pour les groupes de disponibilité :
- Le système de vote majoritaire des nœuds utilise uniquement les votes des nœuds du cluster et fonctionne bien pour les clusters comportant un nombre impair de nœuds.
- La fonctionnalité « Majorité de partage de fichiers et de nœuds » ajoute un vote de témoin de partage de fichiers, adapté aux clusters à nombre pair de nœuds.
- L'utilisation d'un témoin de disque pour la majorité des nœuds et des disques est moins courante pour les groupes de disponibilité, car le stockage partagé n'est pas requis.

3.1.3 Clustering multi-sous-réseaux
Le clustering multi-sous-réseaux permet aux réplicas des groupes de disponibilité de s'étendre sur différents sous-réseaux, prenant ainsi en charge les déploiements géographiquement distribués entre les centres de données. Cette fonctionnalité est essentielle pour les configurations de reprise après sinistre où les réplicas sont situés dans des emplacements distincts.

3.2 SQL Server Configuration requise pour l'édition
3.2.1 Fonctionnalités de l'édition Entreprise
SQL Server L'édition Enterprise offre toutes les fonctionnalités des groupes de disponibilité, sans aucune limitation. Elle prend en charge jusqu'à huit réplicas secondaires, les réplicas secondaires accessibles en lecture, l'amorçage automatique, les groupes de disponibilité distribués et toutes les fonctionnalités avancées.
3.2.2 Fonctionnalités de l'édition standard (groupes de disponibilité de base)
SQL Server L'édition Standard 2016 et les versions ultérieures prennent en charge les groupes de disponibilité de base, mais avec des limitations importantes. Les groupes de disponibilité de base offrent les fonctionnalités essentielles de haute disponibilité à un coût inférieur.ost, convenant aux organisations ayant des exigences plus simples.
4. Configuration des groupes de disponibilité Always On
4.1 Préparation de l'environnement
Avant de créer un groupe de disponibilité, l'environnement doit être correctement préparé avec des comptes Active Directory, des configurations de serveur et une infrastructure réseau en place.
4.1.1 Configuration du contrôleur de domaine
Le contrôleur de domaine Active Directory doit être configuré pour prendre en charge le cluster de groupes de disponibilité et SQL Server comptes de services.
- Connectez-vous au contrôleur de domaine avec les identifiants d'administrateur de domaine.
- Ouvrez Gestionnaire de serveur et naviguez jusqu'à Outils -> Utilisateurs et ordinateurs Active Directory.
- Créer une unité organisationnelle pour SQL Server objets si aucun n'existe.
- Vérifiez que les objets ordinateur de tous les nœuds du cluster existent dans Active Directory.
- Vérifiez que les services DNS (Domain Name System) sont correctement configurés et que tous les noms de serveur sont correctement résolus.
4.1.2 Création de comptes de service
Créez des comptes de service Active Directory dédiés pour SQL Server services sur chaque nœud.
- Ouvrez Utilisateurs et ordinateurs Active Directory sur le contrôleur de domaine.
- Cliquez avec le bouton droit sur l'unité organisationnelle appropriée et sélectionnez NOUVEAU -> L'Utilisateur.
- Saisissez le nom du compte de service (par exemple, svc_SQLServer) et définissez le Nom d'utilisateur.
- Cliquez à nouveau sur Suivant et saisissez un mot de passe fort.
- Choisir L'utilisateur ne peut pas modifier son mot de passe. et Le mot de passe n'expire jamais.
- Cliquez à nouveau sur Suivant et alors Finition pour créer le compte.
- Répétez l'opération pour tout compte de service supplémentaire nécessaire (SQL Server Agent, SSRS, etc.).
4.1.3 Configuration des autorisations d'administrateur
Les comptes de service et les comptes utilisés pour configurer SQL Server doit disposer des autorisations appropriées sur tous les nœuds du cluster.
- Connectez-vous à chaque serveur de nœud du cluster.
- Ouvrez Gestion de l'ordinateur du Commencer menu ou Gestionnaire de serveur.
- Afficher Utilisateurs et groupes locaux et sélectionnez Groupes.
- Faites un clic droit Administrateurs et sélectionnez Propriétés.
- Cliquez à nouveau sur Ajouter et saisissez le nom du compte de service.
- Cliquez à nouveau sur Vérifier les noms pour valider le compte, cliquez ensuite OK.
- Cliquez à nouveau sur OK pour fermer la boîte de dialogue Propriétés de l'administrateur.
- Répétez l'opération sur tous les nœuds du cluster.
4.2 Installation et configuration de WSFC
Le clustering de basculement Windows Server doit être installé et configuré sur tous les nœuds avant d'activer les groupes de disponibilité Always On.
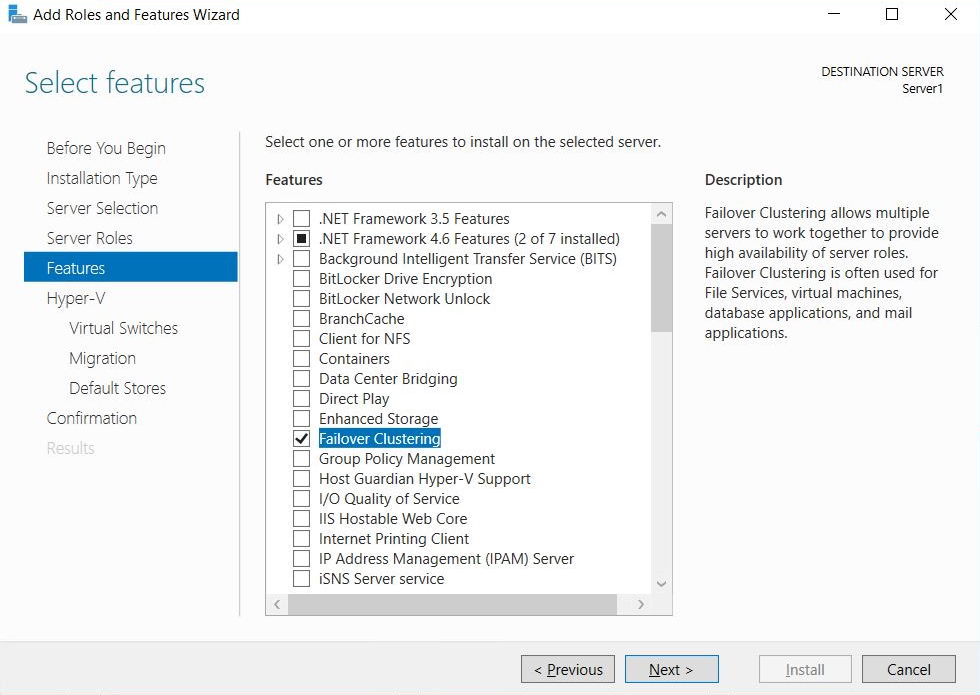
4.2.1 Installation de la fonctionnalité de clustering de basculement
Installez la fonctionnalité de clustering de basculement sur chaque serveur participant au groupe de disponibilité.
- Ouvrez Gestionnaire de serveur sur le premier nœud du cluster.
- Cliquez à nouveau sur Gérer -> Ajouter des rôles et des fonctionnalités.
- Cliquez à nouveau sur Suivant à travers les écrans d'introduction.
- Choisir Installation basée sur des rôles ou des fonctionnalités et cliquez sur Suivant.
- Sélectionnez le serveur local et cliquez Suivant.
- Ignorez l'écran des rôles et cliquez Suivant.
- Sur l'écran Fonctionnalités, sélectionnez Clustering de basculement.
- Cliquez à nouveau sur Ajouter des fonctionnalités lorsqu'on vous invite à inclure des outils de gestion.
- Cliquez à nouveau sur Suivant et alors Installer.
- Attendez que l'installation soit terminée et cliquez Fermer.
- Répétez l'opération sur tous les serveurs qui participeront au cluster.
4.2.2 Création du cluster de basculement
Après avoir installé la fonctionnalité de clustering de basculement sur tous les nœuds, créez le cluster à partir d'un seul nœud.
- Ouvrez Gestionnaire de cluster de basculement à partir de Gestionnaire de serveur -> Outils.
- Cliquez à nouveau sur Créer un cluster dans le volet Actions.
- Cliquez à nouveau sur Suivant sur la page Avant de commencer.
- Cliquez à nouveau sur Explorer et ajoutez tous les serveurs qui deviendront des nœuds du cluster.
- Cliquez à nouveau sur Suivant après avoir ajouté tous les nœuds.
- Quitter Exécutez tous les tests (recommandé) sélectionné et cliquez Suivant.
- Examinez les résultats des tests de validation et corrigez les erreurs ou les avertissements.
- Cliquez à nouveau sur Finition après la validation réussie.
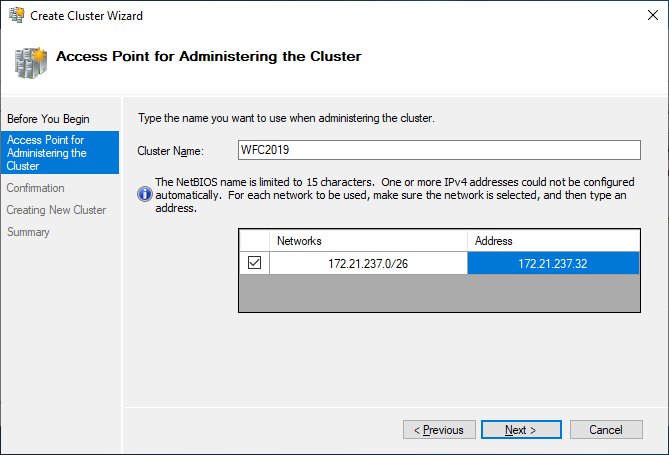
- Saisissez un nom pour le cluster et une adresse IP.
- Décocher Ajouter tout le stockage éligible au cluster car le stockage partagé n'est pas nécessaire.
- Cliquez à nouveau sur Suivant et vérifiez la confirmation.
- Cliquez à nouveau sur Finition pour créer le cluster.
4.2.3 Validation de la configuration du cluster
Validez la configuration du cluster pour vous assurer que tous les nœuds peuvent communiquer correctement et que le cluster fonctionne correctement.
- In Gestionnaire de cluster de basculement, cliquez avec le bouton droit sur le nom du cluster.
- Choisir Valider le cluster dans le menu.
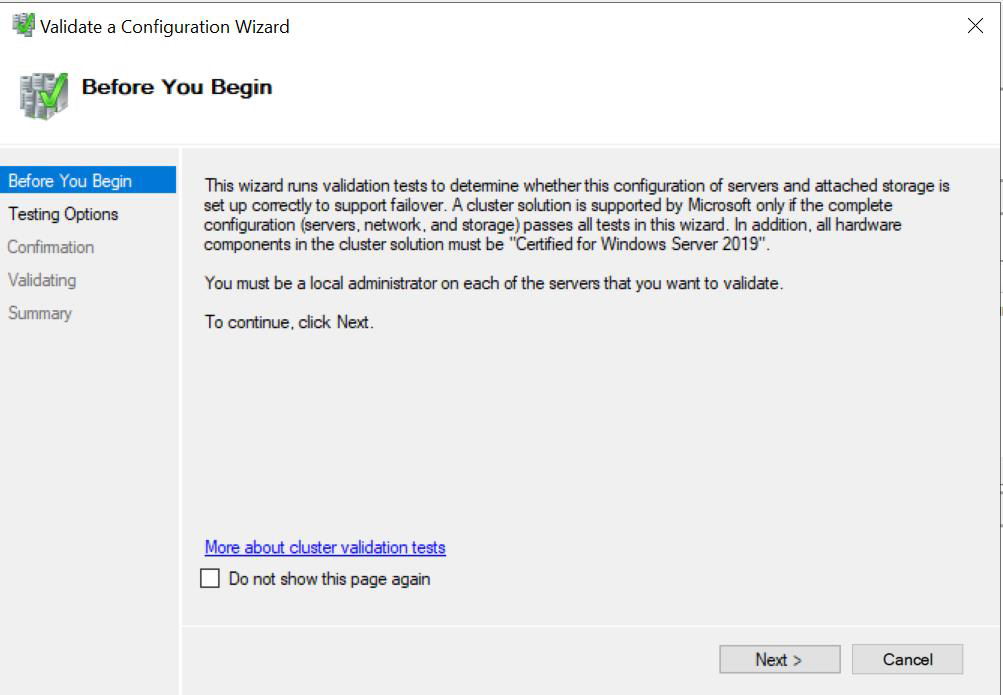
- Cliquez à nouveau sur Suivant sur la page Avant de commencer.
- Choisir Exécutez tous les tests (recommandé) et cliquez sur Suivant.
- Cliquez à nouveau sur Suivant pour commencer les tests de validation.
- Examinez le rapport de validation une fois les tests terminés.
- Corrigez toute défaillance ou tout avertissement identifié dans le rapport.
- Cliquez à nouveau sur Finition pour fermer l'assistant.
4.3 Installation SQL Server pour les groupes de disponibilité
Installer SQL Server sur chaque nœud qui participera au groupe de disponibilité en utilisant l'option d'installation autonome.
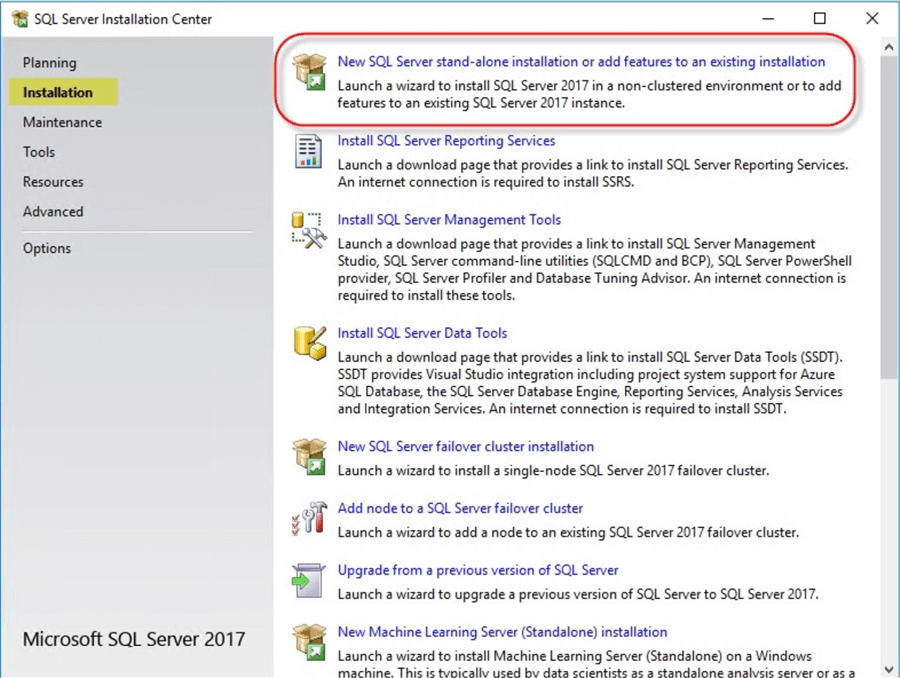
- Exécutez le SQL Server support d'installation sur le premier nœud.
- Choisir NOUVEAU SQL Server installation autonome.
- Saisissez la clé de produit ou sélectionnez la version d'évaluation.
- Acceptez les termes de la licence et cliquez sur Suivant.
- Effectuez les vérifications préalables et résolvez tout problème.
- Sur la page de sélection des fonctionnalités, sélectionnez Services de moteur de base de données.
- Configurez le nom de l'instance (utilisez le même nom d'instance sur tous les nœuds).
- Sur la page de configuration du serveur, spécifiez les informations d'identification du compte de service.
- Configurer le service startypes de tup comme Automatique.
- Sur la page de configuration du moteur de base de données, sélectionnez le mode d'authentification.
- Ajouter des comptes d'administrateur.
- Configurez les répertoires de données en utilisant des chemins d'accès cohérents sur tous les nœuds.
- Terminez l'installation et vérifiez qu'elle a réussi.
- Répétez l'installation sur tous les autres nœuds du cluster avec des paramètres identiques.
4.4 Activation de la fonctionnalité Groupes de disponibilité Always On
Après l'installation de SQL Server Sur tous les nœuds, activez la fonctionnalité Groupes de disponibilité Always On sur chaque instance.
4.4.1 Activation via SQL Server Panneau de configuration
Utilisez le SQL Server Gestionnaire de configuration pour activer les groupes de disponibilité Always On via l'interface graphique.
- Ouvrez SQL Server Panneau de configuration sur le premier nœud.
- Afficher SQL Server Services dans le volet de gauche.
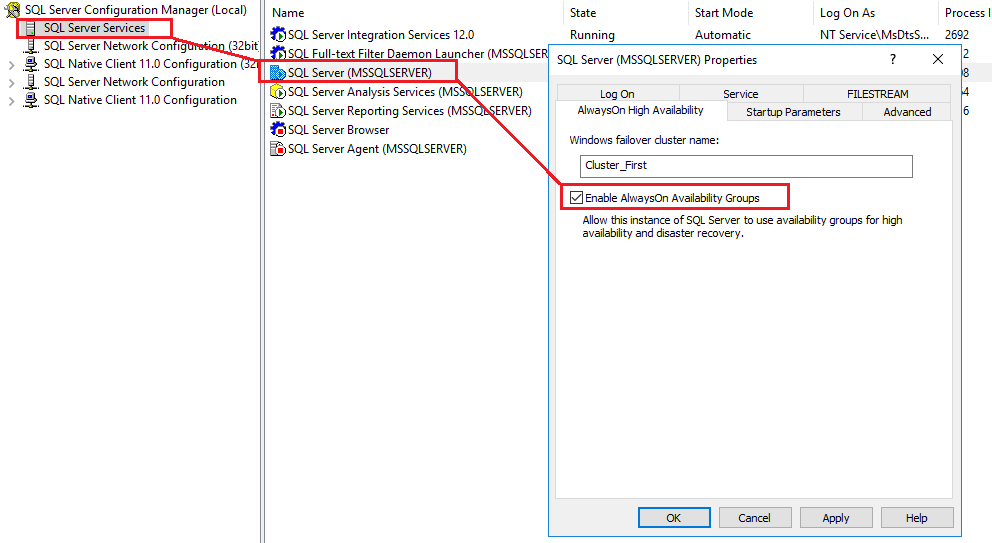
- Faites un clic droit sur le SQL Server instance et sélectionnez Propriétés.
- Cliquez sur Haute disponibilité permanente languette.
- Vérifiez Activer les groupes de disponibilité AlwaysOn.
- Vérifiez que le nom du cluster de basculement Windows est correct.
- Cliquez à nouveau sur OK pour enregistrer les modifications.
- Cliquez à nouveau sur OK sur l'avertissement selon lequel le service doit être restarTed.
- Faites un clic droit sur le SQL Server service et sélectionnez Recommencer.
- Attendez que le service soit rétablitaravec succès.
- Répétez l'opération sur tous les nœuds du cluster.
4.4.2 Activation via PowerShell
PowerShell propose une méthode par script pour activer les groupes de disponibilité Always On sur plusieurs nœuds.
- Ouvrez PowerShell en tant qu'administrateur sur le premier nœud.
- Importer le SQL Server Module PowerShell :
Import-Module SQLPS -DisableNameChecking
- Activer les groupes de disponibilité Always On :
Enable-SqlAlwaysOn -ServerInstance "ServerName\InstanceName" -Force
- Le service se rechargera automatiquementtart lors de l'utilisation du paramètre Force.
- Vérifiez que la fonctionnalité est activée :
Get-ItemProperty "SQLSERVER:\SQL\ServerName\InstanceName" | Select-Object IsHadrEnabled
- Répétez l'opération pour chaque nœud du cluster, en remplaçant les noms de serveur et d'instance appropriés.
4.4.3 Vérification de l'activation de la fonctionnalité
Vérifiez que les groupes de disponibilité Always On sont activés sur toutes les instances avant de procéder à la configuration.
- Connectez-vous à chaque SQL Server instance utilisant SQL Server Atelier de gestion.
- Ouvrez une nouvelle fenêtre de requête et exécutez :
SELECT SERVERPROPERTY('IsHadrEnabled') - Vérifiez que le résultat est 1 (activé).
- Vérifiez que le SQL Server L'instance apparaît dans le Gestionnaire de cluster de basculement sous les rôles du cluster.
- Vérifiez l'existence du point de terminaison du groupe de disponibilité en exécutant :
SELECT * FROM sys.endpoints WHERE type_desc = 'DATABASE_MIRRORING'
- Si le point de terminaison n'existe pas, il sera créé lors de la création du groupe de disponibilité.
4.5 Préparation des bases de données pour les groupes de disponibilité
Les bases de données doivent répondre à des exigences spécifiques avant de pouvoir être ajoutées à un groupe de disponibilité.
4.5.1 Exigences du modèle de récupération de base de données
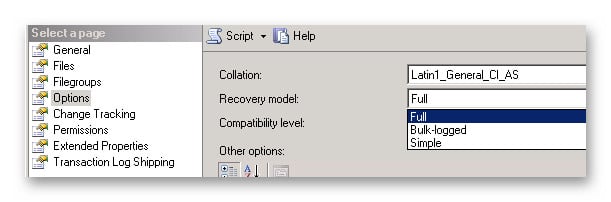
Modifiez le modèle de récupération de la base de données en FULL sur le réplica principal avant de l'ajouter à un groupe de disponibilité.
- Connectez-vous au réplica principal en utilisant SQL Server Atelier de gestion.
- Cliquez avec le bouton droit sur la base de données et sélectionnez Propriétés.
- Sélectionnez le Options .
- Changer Modèle de rétablissement à Full.
- Cliquez à nouveau sur OK pour enregistrer le changement.
- Vous pouvez également utiliser Transact-SQL :
ALTER DATABASE DatabaseName SET RECOVERY FULL;
4.5.2 Sauvegarde complète de la base de données
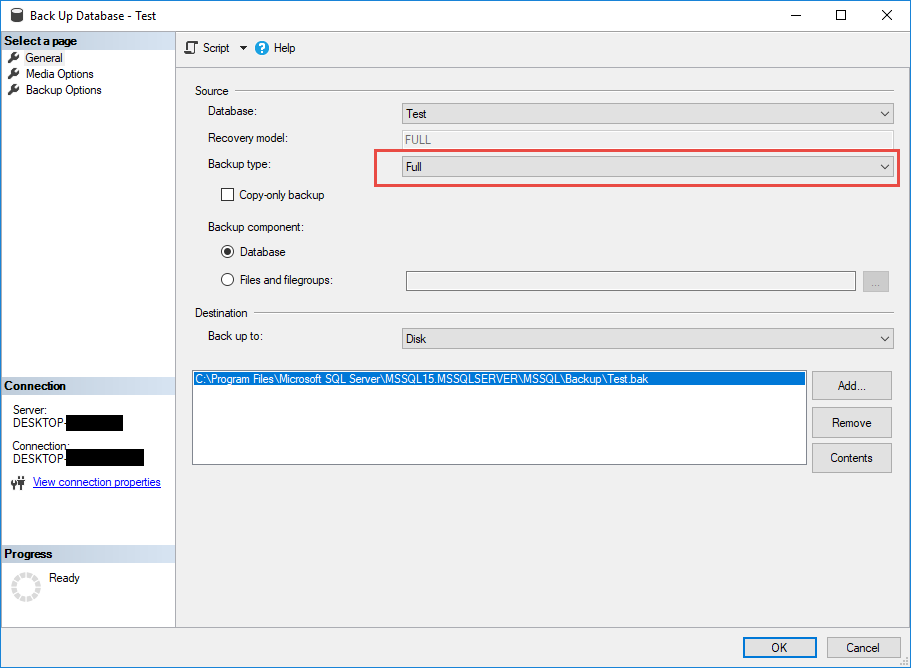
Effectuez une sauvegarde complète de la base de données afin d'établir la chaîne de sauvegarde requise pour les groupes de disponibilité.
- In SQL Server Dans Management Studio, cliquez avec le bouton droit sur la base de données.
- Choisir Tâches -> Sauvegarde.
- Vérifier Type de sauvegarde est fixé à Full.
- Sélectionnez une destination de sauvegarde ou ajoutez une nouvelle destination.
- Cliquez à nouveau sur OK pour effectuer la sauvegarde.
- Vous pouvez également utiliser Transact-SQL :
BACKUP DATABASE DatabaseName TO DISK = 'C:\Backup\DatabaseName.bak';
4.5.3 Sauvegarde des journaux de transactions
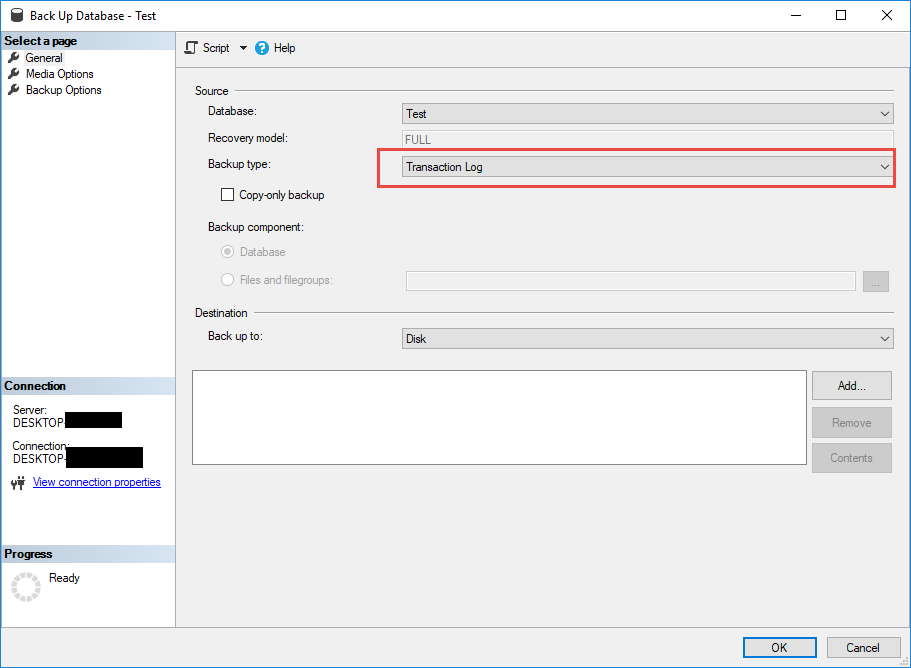
Effectuez une sauvegarde du journal des transactions pour garantir l'établissement de la chaîne de journaux et minimiser le temps d'initialisation.
- In SQL Server Dans Management Studio, cliquez avec le bouton droit sur la base de données.
- Choisir Tâches -> Sauvegarde.
- Changer Type de sauvegarde à Journal des transactions.
- Sélectionnez une destination de sauvegarde.
- Cliquez à nouveau sur OK pour effectuer la sauvegarde.
- Vous pouvez également utiliser Transact-SQL :
BACKUP LOG DatabaseName TO DISK = 'C:\Backup\DatabaseName.trn';
4.6 Création du groupe de disponibilité
Créez le groupe de disponibilité en utilisant l'une des méthodes disponibles, selon vos préférences et vos besoins d'automatisation.
4.6.1 Utilisation de l'Assistant Nouveau groupe de disponibilité
L'assistant de création de groupes de disponibilité fournit une interface graphique pour la création de groupes de disponibilité.
- In SQL Server Management Studio, connectez-vous à l'instance qui va host la réplique principale.
- Afficher Haute disponibilité permanente dans l'explorateur d'objets.
- Faites un clic droit Groupes de disponibilité et sélectionnez Assistant de groupe de disponibilité.

- Cliquez à nouveau sur Suivant sur la page d'introduction.
- Saisissez un nom pour le groupe de disponibilité et cliquez Suivant.
- Sur la page Sélectionner les bases de données, sélectionnez les bases de données à inclure.
- Vérifiez que les bases de données répondent à toutes les conditions préalables et cliquez Suivant.
- Sur la page Spécifier les répliques, cliquez Ajouter une réplique.
- Connectez-vous à chaque instance de réplica secondaire.
- Configurez les propriétés de réplication pour chaque instance (mode de disponibilité, mode de basculement).
- Cliquez sur Endpoints Onglet et vérification de la configuration du point de terminaison.
- Cliquez sur Préférences de sauvegarde Onglet et configurez les priorités de sauvegarde.
- Cliquez sur Auditeur Appuyez sur l'onglet et créez éventuellement un écouteur.
- Cliquez à nouveau sur Suivant et sélectionnez la méthode de synchronisation des données.
- Examiner les résultats de la validation et résoudre les problèmes éventuels.
- Cliquez à nouveau sur Suivant et consultez le résumé.
- Cliquez à nouveau sur Finition pour créer le groupe de disponibilité.
- Surveillez l'avancement et vérifiez la réussite de la création.
4.6.2 Utilisation de Transact-SQL
Créez des groupes de disponibilité à l'aide de Transact-SQL pour des déploiements scriptables et reproductibles.
- Créez le groupe de disponibilité sur le réplica principal :
CREATE AVAILABILITY GROUP AG_Name FOR DATABASE DatabaseName REPLICA ON 'PrimaryServer\Instance' WITH (ENDPOINT_URL = 'TCP://PrimaryServer:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL)), 'SecondaryServer\Instance' WITH (ENDPOINT_URL = 'TCP://SecondaryServer:5022', AVAILABILITY_MODE = SYNCHRONOUS_COMMIT, FAILOVER_MODE = AUTOMATIC, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL)); - Ajoutez le réplica secondaire au groupe de disponibilité :
ALTER AVAILABILITY GROUP AG_Name JOIN;
- Rejoignez la base de données secondaire :
ALTER DATABASE DatabaseName SET HADR AVAILABILITY GROUP = AG_Name;
4.6.3 Utilisation de PowerShell
PowerShell offre des fonctionnalités de script pour la création et la gestion des groupes de disponibilité.
- Créez l'objet groupe de disponibilité :
$AG = New-SqlAvailabilityGroup -Name "AG_Name" -Path "SQLSERVER:\SQL\PrimaryServer\Instance"
- Ajouter des bases de données :
Add-SqlAvailabilityDatabase -Path "SQLSERVER:\SQL\PrimaryServer\Instance\AvailabilityGroups\AG_Name" -Database "DatabaseName"
- Configurez les réplicas avec les propriétés souhaitées à l'aide de l'applet de commande New-SqlAvailabilityReplica.
- Joignez les réplicas secondaires à l'aide de l'applet de commande Join-SqlAvailabilityGroup.
4.7 Ajout de réplicas au groupe de disponibilité
Configurez les propriétés spécifiques à chaque réplique qui contrôlent la manière dont chaque instance participe au groupe de disponibilité.
4.7.1 Configuration des propriétés de la réplique
Définissez les propriétés de chaque réplique afin de définir son rôle et ses capacités au sein du groupe de disponibilité.
- In SQL Server Studio de gestion, développer Haute disponibilité permanente -> Groupes de disponibilité.
- Développez le groupe de disponibilité, puis développez-le. Disponibilité des répliques.

- Faites un clic droit sur une réplique et sélectionnez Propriétés.
- Vérifiez et modifiez les paramètres de connexion pour les rôles principal et secondaire.
- Configurez les valeurs de délai d'expiration de session si nécessaire.
- Cliquez à nouveau sur OK enregistrer les modifications
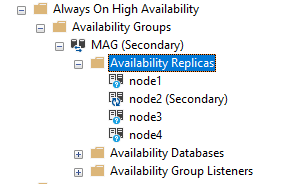
4.7.2 Configuration des modes de disponibilité
Configurez le mode de disponibilité pour contrôler le comportement de synchronisation entre les répliques.
- Cliquez avec le bouton droit sur le groupe de disponibilité et sélectionnez Propriétés.
- Dans l' Généralités page, allez à la Disponibilité des répliques .
- Pour chaque réplique, sélectionnez Validation synchrone or Validation asynchrone de la liste déroulante.
- Utilisez la validation synchrone pour les réplicas locaux à haute disponibilité.
- Utilisez la validation asynchrone pour les répliques de reprise après sinistre géographiquement distantes.
- Cliquez à nouveau sur OK pour enregistrer la configuration.
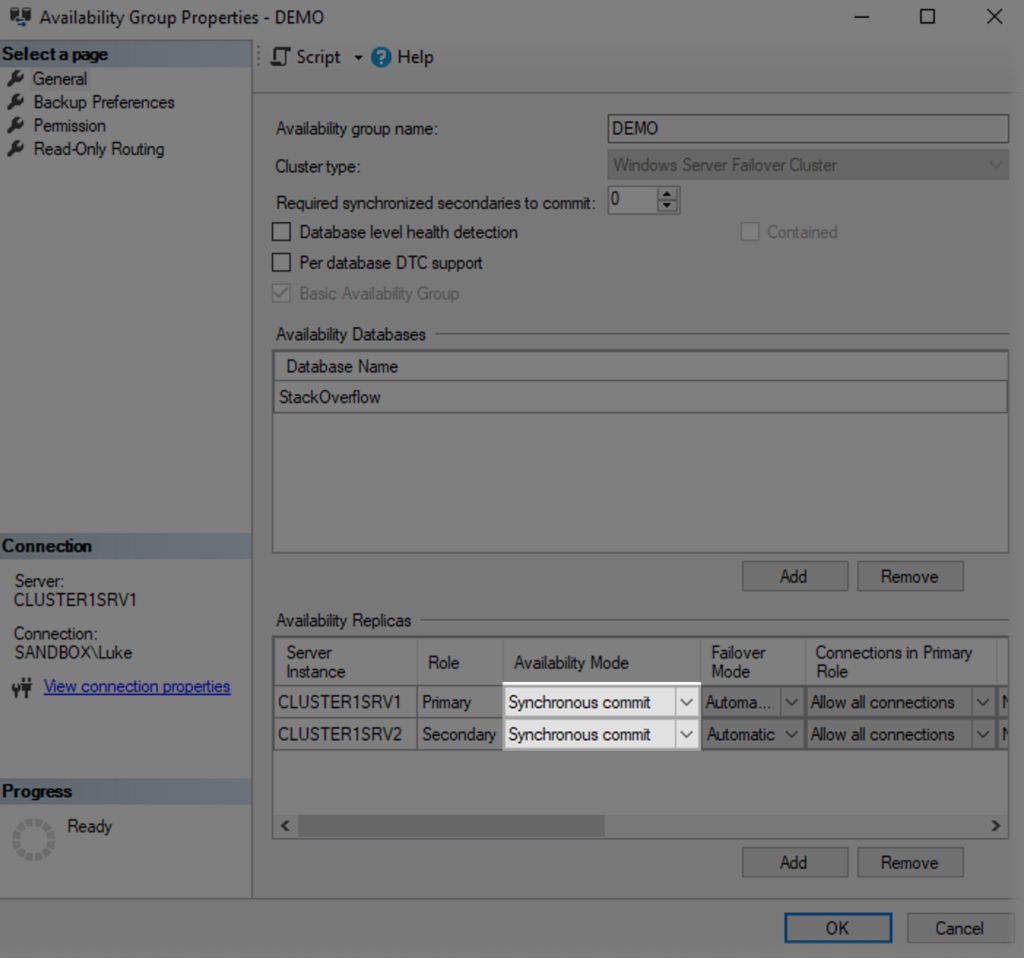
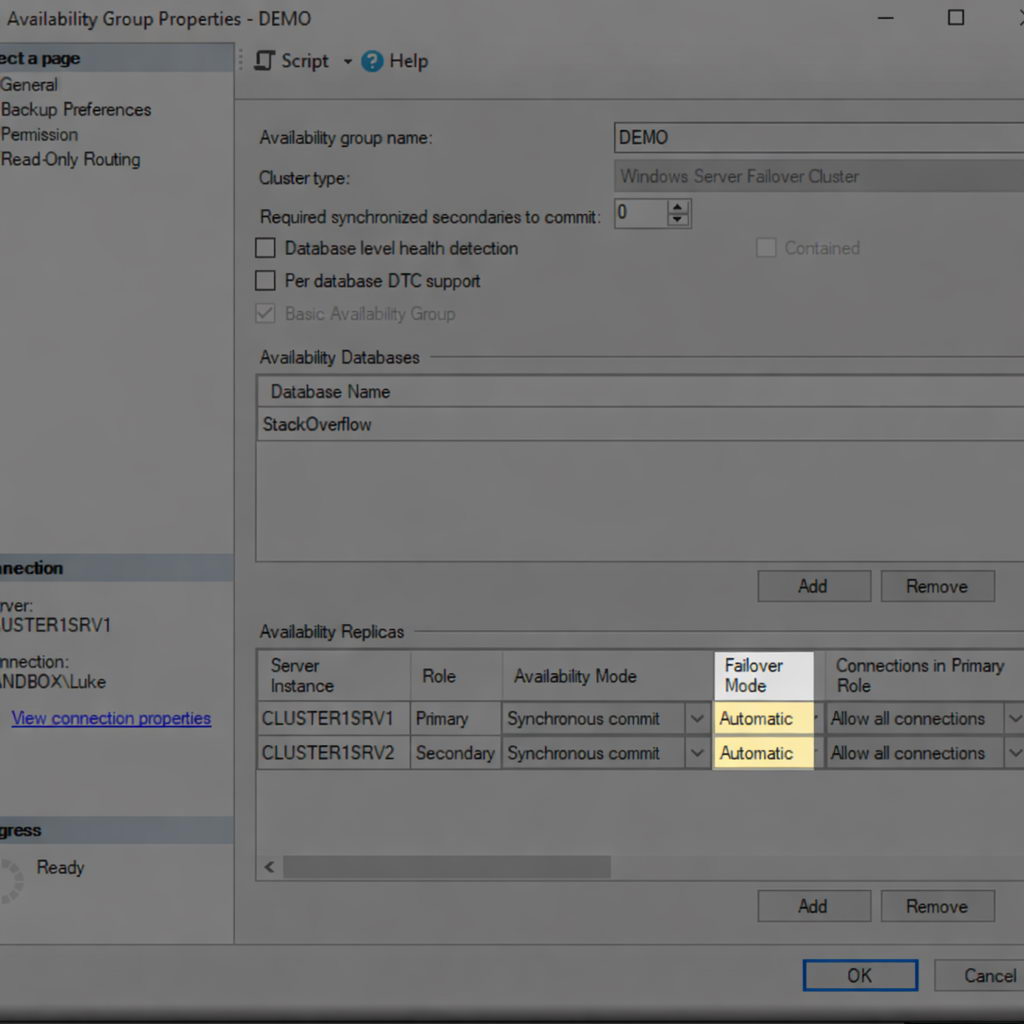
4.7.3 Configuration des modes de basculement
Configurez le mode de basculement pour contrôler la manière dont le basculement se produit pour chaque réplique.
- Cliquez avec le bouton droit sur le groupe de disponibilité et sélectionnez Propriétés.
- Dans l' Généralités page, allez à la Disponibilité des répliques .
- Pour les réplicas de validation synchrone, sélectionnez Automatique or Manuel mode de basculement.
- Le basculement automatique nécessite un mode de validation synchrone et permet un basculement sans intervention humaine.
- Pour les réplicas de validation asynchrones, seul le basculement manuel est disponible.
- Configurez jusqu'à trois répliques pour le basculement automatique (une principale et deux secondaires).
- Cliquez à nouveau sur OK appliquer les paramètres.
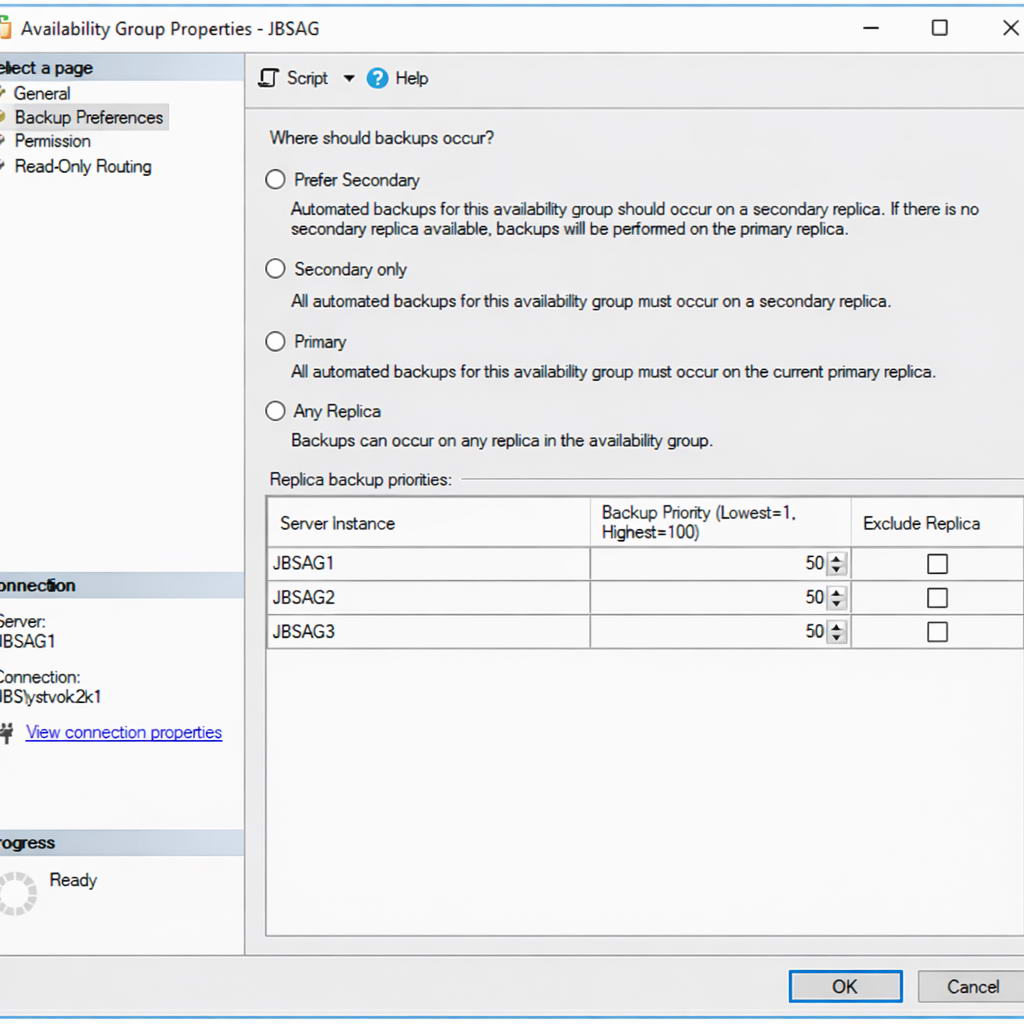
4.7.4 Configuration des préférences de sauvegarde
Définissez les préférences de sauvegarde pour contrôler l'emplacement où les opérations de sauvegarde doivent avoir lieu.
- Cliquez avec le bouton droit sur le groupe de disponibilité et sélectionnez Propriétés.
- Choisir Préférences de sauvegarde dans le volet de gauche.
- Choisissez l'une des préférences de sauvegarde :
- Préférer le secondaireSauvegarde sur le serveur secondaire si disponible, sinon sur le serveur principal.
- Secondaire seulement: Sauvegardes uniquement sur les répliques secondaires
- PrimaireSauvegardes uniquement sur le réplica principal
- Toute réplique: Sauvegardes sur toute réplique disponible
- Définissez les valeurs de priorité de sauvegarde pour chaque réplique (0-100).
- Des valeurs de priorité plus élevées indiquent une sauvegarde préférée tarobtient.
- Cliquez à nouveau sur OK pour enregistrer les préférences.
4.8 Configuration de l'écouteur du groupe de disponibilité
Créez un écouteur pour fournir un point de connexion unique qui redirige automatiquement vers le réplica principal actuel.
4.8.1 Création de l'écouteur
Ajoutez un écouteur au groupe de disponibilité pour la gestion des connexions client.
- In SQL Server Management Studio, développez le groupe de disponibilité.
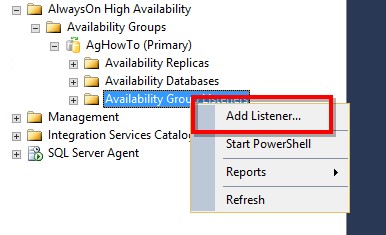
- Faites un clic droit Écouteurs du groupe de disponibilité et sélectionnez Ajouter un écouteur.

- Saisissez un nom DNS pour l'écouteur (par exemple, AG_Listener).
- Saisissez le numéro de port (par défaut : 1433).
- Choisir IP statique pour le mode réseau.
- Cliquez à nouveau sur Ajouter ajouter une adresse IP pour chaque sous-réseau.
- Saisissez l'adresse IP et sélectionnez le sous-réseau.
- Cliquez à nouveau sur OK pour créer l'écouteur.
- Vérifiez que l'écouteur apparaît dans l'explorateur d'objets et qu'il est en ligne.
4.8.2 Configuration des paramètres DNS et IP
Vérifiez l'enregistrement DNS et la configuration réseau du serveur d'écoute.
- Ouvrez le Gestionnaire DNS sur le contrôleur de domaine.
- Vérifiez que le nom de l'écouteur a bien été enregistré auprès de toutes les adresses IP.
- Tester la résolution DNS depuis les machines clientes :
nslookup ListenerName
- Vérifiez que toutes les adresses IP configurées sont renvoyées.
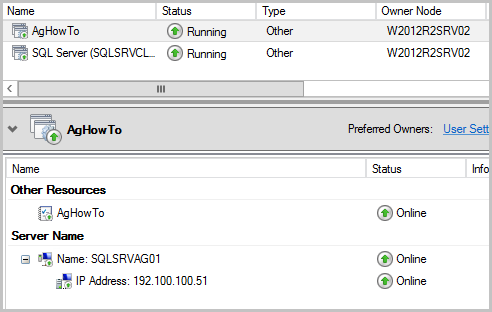
- Dans le Gestionnaire de cluster de basculement, développez Rôles et sélectionnez le groupe de disponibilité.
- Vérifiez que les ressources de l'adresse IP sont en ligne.
- Vérifiez que la ressource de nom de réseau est en ligne.

4.8.3 Test de connectivité de l'écouteur
Vérifiez que les applications clientes peuvent se connecter via l'écouteur.
- Depuis un poste client, ouvrez SQL Server Atelier de gestion.
- Connectez-vous en utilisant le nom de l'écouteur au lieu du nom du serveur.
- Exécutez une requête pour vérifier la connexion au réplica principal actuel :
SELECT @@SERVERNAME;
- Testez le routage en lecture seule en ajoutant ApplicationIntent=ReadOnly à la chaîne de connexion.
- Vérifiez que la connexion redirige bien vers une réplique secondaire lisible.
- Tester le basculement en faisant basculer manuellement le groupe de disponibilité et en vérifiant la reconnexion.
4.9 Méthodes de synchronisation des données
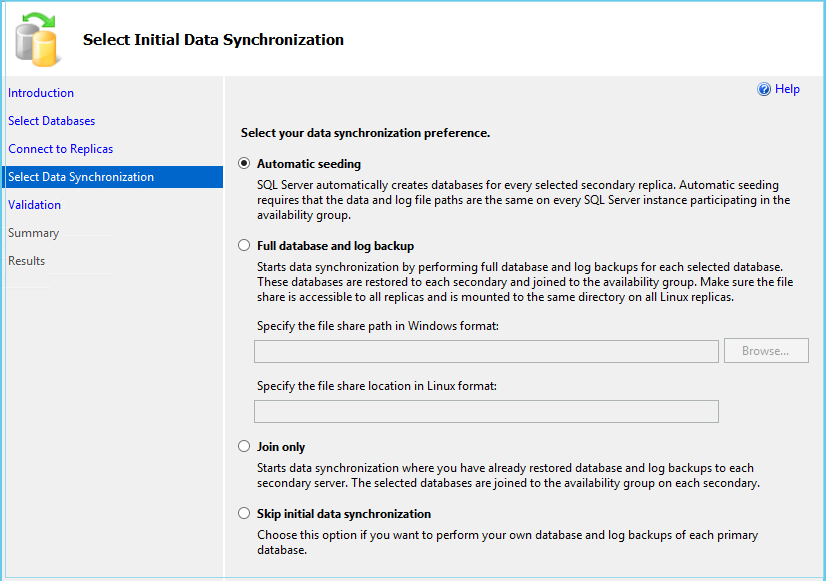
Choisissez une méthode de synchronisation des données pour initialiser les répliques secondaires avec des copies de la base de données.
4.9.1 Semis automatique
L'amorçage automatique transfère les données de la base de données sur le réseau sans nécessiter de sauvegardes et de restaurations manuelles.
- Lors de la création du groupe de disponibilité, sélectionnez Semis automatique comme méthode de synchronisation.

- Assurez la connectivité réseau et une bande passante suffisante entre les répliques.
- La réplique principale transmet automatiquement les données de la base de données aux répliques secondaires.
- Surveillez la progression de l'ensemencement à l'aide du tableau de bord du groupe de disponibilité ou des DMV.
- L'ensemencement automatique nécessite SQL Server 2016 ou plus tard.
- Pour les bases de données volumineuses, tenez compte de l'impact sur le réseau et planifiez les opérations pendant les périodes de faible utilisation.
4.9.2 Semis manuel (Sauvegarde et restauration)
L'amorçage manuel consiste à effectuer des sauvegardes sur le serveur principal et à les restaurer sur des répliques secondaires.
- Sur la réplique principale, effectuez une sauvegarde complète :
BACKUP DATABASE DatabaseName TO DISK = '\\SharePath\DatabaseName.bak';
- Effectuez une sauvegarde du journal des transactions :
BACKUP LOG DatabaseName TO DISK = '\\SharePath\DatabaseName.trn';
- Sur chaque réplique secondaire, restaurez la sauvegarde complète :
RESTORE DATABASE DatabaseName FROM DISK = '\\SharePath\DatabaseName.bak' WITH NORECOVERY;
- Restaurez la sauvegarde du journal :
RESTORE LOG DatabaseName FROM DISK = '\\SharePath\DatabaseName.trn' WITH NORECOVERY;
- Intégrez la base de données au groupe de disponibilité :
ALTER DATABASE DatabaseName SET HADR AVAILABILITY GROUP = AG_Name;
- Vérifiez que la synchronisation démarre et que la base de données atteint l'état SYNCHRONISÉ.
4.9.3 Fichiers d'instantané de base de données
Utilisez les fichiers d'instantané de base de données pour initialiser les répliques secondaires à partir des fichiers de base de données existants.
- Détachez ou sauvegardez la base de données sur le réplica principal.
- Copiez les fichiers de base de données sur chaque réplique secondaire en utilisant les mêmes chemins d'accès.
- Sur les répliques secondaires, attachez la base de données ou restaurez-la sans récupération.
- Assurez-vous que la base de données est en état de RESTAURATION.
- Intégrez la base de données au groupe de disponibilité.
- Cette méthode est utile pour les très grandes bases de données où le transfert réseau serait impraticable.
5. FAQ
5.1 Questions Générales
Q : Quelle est la différence entre Always On FCI et Always On AG ?
A : Les instances de cluster de basculement Always On offrent une haute disponibilité au niveau de l'instance grâce à un stockage partagé, tandis que les groupes de disponibilité Always On offrent une haute disponibilité au niveau de la base de données sans stockage partagé. Les groupes de disponibilité proposent des disques secondaires accessibles en lecture et une distribution géographique plus flexible.
Q : Puis-je utiliser les groupes de disponibilité Always On avec SQL Server Édition standard ?
Un: oui, SQL Server L'édition Standard 2016 et les versions ultérieures prennent en charge les groupes de disponibilité de base avec des limitations, notamment une base de données par groupe de disponibilité, deux réplicas maximum et aucune prise en charge secondaire en lecture.
Q : Ai-je besoin d'un stockage partagé pour les groupes de disponibilité Always On ?
R : Non, les groupes de disponibilité ne nécessitent pas de stockage partagé. Chaque réplique conserve des copies indépendantes des bases de données sur un stockage local, synchronisées par la réplication des journaux de transactions.
Q : Quel est le nombre maximal de réplicas dans un groupe de disponibilité ?
A: SQL Server L'édition Enterprise prend en charge jusqu'à neuf réplicas (un principal et huit secondaires). Les groupes de disponibilité distribués peuvent prendre en charge jusqu'à 18 réplicas au total, répartis sur deux groupes de disponibilité.
5.2 Questions de configuration
Q : Comment choisir entre les modes de validation synchrone et asynchrone ?
A : Utilisez la validation synchrone pour garantir l'absence de perte de données au sein d'un même centre de données ou sur des réseaux à faible latence. Utilisez la validation asynchrone pour les répliques de reprise après sinistre distantes où la validation synchrone impacterait les performances.
Q : Puis-je mélanger des réplicas synchrones et asynchrones dans le même groupe de disponibilité ?
R : Oui, les groupes de disponibilité prennent en charge les configurations mixtes avec des réplicas synchrones et asynchrones. Cela permet une haute disponibilité locale avec des réplicas synchrones et une reprise après sinistre à distance avec des réplicas asynchrones.
Q : Que se passe-t-il avec mes connexions pendant un basculement ?
A : Les connexions existantes sont interrompues lors d'un basculement. Les applications dotées d'une logique de nouvelle tentative de connexion se reconnectent automatiquement au nouveau serveur principal via l'écouteur. Le processus de basculement s'achève généralement en quelques secondes à quelques minutes.
Q : Dois-je synchroniser les connexions et les tâches entre les réplicas ?
A: dans SQL Server Pour les versions 2019 et antérieures, oui – les connexions, les tâches de l'agent SQL et les serveurs liés doivent être synchronisés manuellement. SQL Server La version 2022 introduit les groupes de disponibilité contenus qui incluent automatiquement ces objets.
5.3 Questions de gestion
Q : Puis-je effectuer des sauvegardes sur des répliques secondaires ?
R : Oui, les répliques secondaires prennent en charge les sauvegardes complètes, différentielles et du journal des transactions. Configurez les préférences de sauvegarde pour décharger la réplique principale et réduire ainsi son utilisation des ressources.
Q : Comment puis-je effectuer la mise à jour ? SQL Server avec un temps d'arrêt minimal ?
A : Utilisez les mises à niveau progressives en appliquant d'abord les correctifs aux répliques secondaires, puis en effectuant un basculement manuel vers une réplique secondaire corrigée, et enfin en appliquant les correctifs à l'ancienne réplique principale. Cela réduit le temps d'indisponibilité à la durée du basculement.
Q : Puis-je ajouter des bases de données à un groupe de disponibilité existant ?
R : Oui, il est possible d'ajouter des bases de données aux groupes de disponibilité en cours d'exécution. La base de données doit être en mode de récupération complète avec une sauvegarde complète, et les réplicas secondaires doivent être initialisés automatiquement ou manuellement par sauvegarde et restauration.
Q : Qu'est-ce que l'ensemencement automatique et dois-je l'utiliser ?
A : L'amorçage automatique transfère les données de la base de données via le réseau pour initialiser les répliques secondaires sans sauvegarde manuelle. Utilisez-le pour les petites bases de données ou lorsque la bande passante réseau est suffisante. Pour les très grandes bases de données, l'amorçage manuel peut être plus rapide.
Q : Où dois-je exécuter DBCC CHECKDB dans un groupe de disponibilité ?
A : Il est recommandé d'exécuter DBCC CHECKDB sur les réplicas secondaires afin de réduire la charge sur le réplica principal. Les contrôles de cohérence de la base de données peuvent être exécutés sur les bases de données secondaires sans impacter les performances du réplica principal.
Pour plus de détails sur DBCC CHECKDB, consultez notre documentation. guide complet.
5.4 Questions de dépannage
Q : Pourquoi ma base de données est-elle en état NON SYNCHRONISÉE ?
A : Les causes courantes incluent les problèmes de connectivité réseau, l'interruption des transferts de données, l'espace disque insuffisant sur les réplicas secondaires ou les problèmes de point de terminaison. Consultez la description de l'état de la synchronisation et SQL Server Consultez les journaux d'erreurs pour plus de détails. Si la base de données secondaire a enregistré une erreur, état de récupération ou spectacles récupération en cours, consultez les guides liés pour tarLes correctifs ont été obtenus.
Q : Comment forcer le basculement lorsque le serveur principal est indisponible ?
A : Connectez-vous à un réplica secondaire et exécutez la commande ALTER AVAILABILITY GROUP AG_Name FORCE_FAILOVER_ALLOW_DATA_LOSS. Cette opération prend en compte la perte potentielle de données et promeut immédiatement le réplica secondaire en réplica principal.
Q : Pourquoi les clients ne peuvent-ils pas se connecter à mon écouteur ?
A : Vérifiez que l'écouteur est en ligne dans le Gestionnaire de cluster de basculement, que l'enregistrement DNS a réussi, que toutes les adresses IP de l'écouteur sont accessibles depuis les clients et que les règles du pare-feu autorisent le trafic vers le port de l'écouteur.
Q : Que signifie une file d'attente de restauration importante ?
A : Une file d'attente de restauration importante indique que le réplica secondaire ne peut pas appliquer les enregistrements de journal aussi rapidement qu'ils arrivent. Cela peut indiquer des goulots d'étranglement au niveau des E/S disque, des limitations du processeur ou un blocage par des requêtes en lecture seule sur le réplica secondaire.
Q : Que dois-je faire si une catastrophe affecte toutes les répliques et que mes sauvegardes sont également corrompues ?
A : Ce scénario catastrophe, bien qu'extrêmement rarCes incidents peuvent survenir suite à des attaques de ransomware, des pannes de stockage généralisées ou des catastrophes en cascade. La prévention est votre principale défense : maintenez des répliques géographiquement distribuées, stockez les sauvegardes dans des emplacements distincts, et
Testez régulièrement vos procédures de reprise après sinistre. Si toutes les options de reprise standard échouent, une procédure spécialisée sera nécessaire. Outil de récupération de données SQL peut tenter d'extraire des données de fichiers MDF endommagés en dernier recours.
5.5 Licences et Cost Questions
Q : Comment les groupes de disponibilité Always On sont-ils concédés sous licence ?
A: SQL Server Les conditions de licence dépendent de l'édition et du modèle de déploiement. Les groupes de disponibilité de l'édition Enterprise requièrent des licences Enterprise sur toutes les répliques. Les répliques secondaires passives peuvent bénéficier d'une licence gratuite sous certaines conditions.
Q : Puis-je utiliser SQL Server Édition développeur pour les groupes de disponibilité ?
R : Oui, l'édition Développeur inclut toutes les fonctionnalités de l'édition Entreprise, y compris la prise en charge complète des groupes de disponibilité. Cependant, sa licence est réservée au développement et aux tests, et non à une utilisation en production.
Q : Les répertoires secondaires lisibles nécessitent-ils des licences supplémentaires ?
A : La gestion des licences dépend du contexte. Les serveurs secondaires passifs pour la reprise après sinistre ne nécessitent généralement pas de licence. Les serveurs secondaires actifs hébergeant des charges de travail en lecture seule requièrent généralement une licence, bien que les conditions spécifiques varient.
Q : Existe-t-il un moyen gratuit d'obtenir une haute disponibilité avec SQL Server?
A: SQL Server L'édition Express ne prend pas en charge les groupes de disponibilité. SQL Server L'édition Standard prend en charge les groupes de disponibilité de base.taravec SQL Server 2016, offrant une haute disponibilité de base avec la licence Standard Edition costs.
Q : Que sont les groupes de disponibilité distribués ?
A : Les groupes de disponibilité distribués sont un type particulier de groupe de disponibilité qui s'étend sur deux groupes de disponibilité distincts, permettant des scénarios qui dépassent les capacités des groupes de disponibilité traditionnels. Introduits en SQL Server En 2016, les groupes de disponibilité distribués répondaient aux exigences de mise à l'échelle et de distribution géographique.
6. Conclusion
6.1 Résumé des points clés
SQL Server Les groupes de disponibilité Always On constituent la solution de pointe de Microsoft en matière de haute disponibilité et de reprise après sinistre pour les bases de données critiques. Ils offrent un basculement au niveau de la base de données sans nécessiter de stockage partagé, des réplicas secondaires accessibles en lecture pour décharger les charges de travail et une distribution géographique flexible pour une protection complète des données. Pour les organisations utilisant encore des solutions telles que… transport de grumes or réplicationLes groupes de disponibilité offrent une voie de mise à niveau plus robuste et plus simple sur le plan opérationnel.
6.2 Quand utiliser les groupes de disponibilité Always On
Choisissez les groupes de disponibilité lorsque vous avez besoin d'une haute disponibilité au niveau de la base de données avec basculement automatique. Les organisations qui exigent une protection zéro perte de données pour leurs bases de données critiques bénéficient de réplicas à validation synchrone avec basculement automatique. Les applications nécessitant une montée en charge en lecture exploitent des réplicas secondaires lisibles pour répartir les charges de travail des requêtes.
6.3 Obtenir Started avec votre mise en œuvre
Commencez la planification des groupes de disponibilité en évaluant les besoins métier, notamment les objectifs de temps de récupération (RTO) et de point de récupération (RPO), ainsi que les contraintes budgétaires. Documentez l'infrastructure de base de données actuelle, les dépendances applicatives et les lacunes en matière de haute disponibilité. Concevez une architecture de groupes de disponibilité qui réponde aux exigences tout en respectant les contraintes de ressources.
Références
- Document officiel de Microsoft : Qu'est-ce qu'un groupe de disponibilité Always On ?
- Document officiel de Microsoft : Obtenir Staravec des groupes de disponibilité Always On
- Document officiel de Microsoft : Groupes de disponibilité distribués
À propos de l’auteur
Yuan Sheng est un administrateur de base de données senior (DBA) avec plus de 10 ans d'expérience dans SQL Server Environnements et gestion de bases de données d'entreprise. Il a résolu avec succès des centaines de scénarios de récupération de bases de données dans des organisations du secteur financier, de la santé et de l'industrie manufacturière.
Yuan se spécialise dans SQL Server Récupération de bases de données, solutions de haute disponibilité et optimisation des performances. Sa vaste expérience pratique comprend la gestion de bases de données de plusieurs téraoctets, la mise en œuvre de groupes de disponibilité permanente (AAL) et le développement de stratégies automatisées de sauvegarde et de restauration pour les systèmes d'entreprise critiques.
Grâce à son expertise technique et à son approche pratique, Yuan se concentre sur la création de guides complets qui aident les administrateurs de bases de données et les professionnels de l'informatique à résoudre des problèmes complexes. SQL Server défis efficacement. Il se tient au courant des dernières SQL Server les versions et les technologies de base de données en constante évolution de Microsoft, testant régulièrement des scénarios de récupération pour garantir que ses recommandations reflètent les meilleures pratiques du monde réel.
Vous avez des questions sur SQL Server Besoin d'aide pour la récupération de votre base de données ? Yuan vous accueille. commentaires et suggestions pour améliorer ces ressources techniques.