1. Présentation de SQL Server réplication
1.1 Qu'est-ce que SQL Server Réplication ?
SQL Server La réplication regroupe un ensemble de technologies permettant de copier et de distribuer des données et des objets de base de données d'une base de données à une autre, puis de synchroniser ces bases pour garantir leur cohérence. Cette fonctionnalité vous permet de créer et de gérer plusieurs copies de vos données sur différents serveurs et emplacements, assurant ainsi leur disponibilité et leur fiabilité.
1.2 Objectif et avantages de la réplication
SQL Server La réplication répond à de multiples besoins critiques des entreprises et offre des avantages significatifs pour la gestion des bases de données et la distribution des données :
- Répartition des données entre les différents sites : La réplication permet de partager des données entre bureaux régionaux ou sites internationaux, améliorant ainsi l'efficacité opérationnelle grâce à un accès local aux données nécessaires. Elle réduit la latence du réseau et offre de meilleures performances aux utilisateurs répartis géographiquement.
- Haute Disponibilité et reprise après sinistre : En conservant des répliques des données critiques sur plusieurs serveurs, la réplication assure une redondance qui protège contre les pannes matérielles et les sinistres. En cas de défaillance du serveur principal, les copies répliquées peuvent servir de sources de secours, minimisant ainsi les interruptions de service et les pertes de données.
- Équilibrage de charge et évolutivité : La réplication répartit les opérations de lecture sur plusieurs serveurs, évitant ainsi qu'un serveur unique ne devienne un goulot d'étranglement. Cette approche améliore les performances du système et permet à votre infrastructure d'évoluer horizontalement en fonction de la croissance des données et des besoins des utilisateurs.
- Rapports et analyses en temps réel : Le déchargement des requêtes de reporting et d'analyse sur des serveurs répliqués réduit la charge sur les bases de données de production. Les utilisateurs peuvent ainsi exécuter des requêtes analytiques complexes sur des données quasi temps réel sans impacter les systèmes opérationnels, garantissant à la fois la performance et la fraîcheur des données.
- Intégration et consolidation des données : La réplication facilite la fusion des données provenant de diverses sources en une vue consolidée unique. Ceci est particulièrement précieux pour les organisations possédant plusieurs succursales qui doivent agréger les données au siège social, ou pour la création d'entrepôts de données centralisés à partir de systèmes opérationnels distribués.
2. SQL Server Architecture et composants de réplication
SQL Server L'architecture de réplication se compose de plusieurs composants interconnectés qui fonctionnent de concert pour distribuer et synchroniser les données au sein de votre infrastructure de base de données. Cette section explore les composants principaux, notamment les éditeurs, les distributeurs, les abonnés, les publications, les articles, les abonnements et les agents qui coordonnent le flux de données entre eux.
- Editeur: Un éditeur est un SQL Server par exemple que hostIl s'agit d'une ou plusieurs bases de données contenant les données à répliquer. Elle sert de source faisant autorité dans la topologie de réplication.
- Distributeur: Un distributeur est un SQL Server instance qui gère le flux de données entre les éditeurs et les abonnés. L'instance de distribution hosts'agit de la base de données de distribution, qui stocke les métadonnées de réplication et les transactions.
- Abonné: Un abonné est un SQL Server instance qui reçoit et stocke les données répliquées des éditeurs. Une seule instance d'abonné peut host Plusieurs bases de données d'abonnés, chacune recevant des données provenant de publications différentes.
- Publication: Une publication définit les données à répliquer et leur mode de distribution aux abonnés. Elle regroupe les articles connexes et établit la méthodologie de réplication applicable à tous les objets qu'elle contient.
- Article: Un article est l'élément de base de la réplication, représentant un objet de base de données individuel qui sera distribué aux abonnés.
- Abonnement: Un abonnement établit la relation entre une publication et un abonné, définissant comment et quand les données sont livrées à la base de données de destination.
- Agents: Les agents sont des processus spécialisés qui effectuent le travail concret de déplacement et de synchronisation des données entre les composants de réplication.

3. Types de SQL Server réplication
SQL Server Il existe plusieurs types de réplication, chacun conçu pour des scénarios de distribution de données et des exigences métier spécifiques. Il est essentiel de comprendre les caractéristiques, les avantages et les limites de chaque type pour choisir la solution la plus adaptée à votre environnement.
3.1 Réplication d'instantané
La réplication par instantané crée un instantané des données à publier à un moment précis, puis distribue cette copie exacte et complète aux abonnés. Elle ne surveille pas les modifications ultérieures jusqu'à la génération du prochain instantané. La réplication par instantané est la forme de réplication la plus simple, ce qui la rend adaptée aux scénarios où les données changent rarement ou lorsqu'une légère obsolescence des données est acceptable.
Les cas d'utilisation courants incluent la distribution de données de référence telles que des listes de prix ou des taux de change mis à jour périodiquement, la fourniture d'ensembles de données initiaux pour les entrepôts de données et les scénarios où une actualisation complète des données est préférable au suivi des modifications individuelles. Par exemple, une entreprise peut utiliser la réplication par instantané pour distribuer quotidiennement des catalogues de produits mis à jour à ses succursales.
Les principaux avantages de la réplication par instantané sont sa simplicité, ses faibles besoins de maintenance et sa capacité à répliquer des données sans clés primaires. Cependant, elle présente des inconvénients importants, notamment un impact élevé lors de la génération d'instantanés dû aux verrous de table, une latence élevée entre les mises à jour et une inefficacité pour les grands ensembles de données ou les données fréquemment modifiées. Toute modification effectuée chez les abonnés est répliquée.ost lors de l'application du prochain instantané.
3.2 Réplication transactionnelle
La réplication transactionnelle permet de diffuser les modifications de l'éditeur aux abonnés en temps quasi réel, en répliquant chaque transaction au fur et à mesure. Elle commence par une capture initiale pour établir la base de référence, puis surveille en continu le journal des transactions afin de détecter les modifications apportées aux articles publiés et de les diffuser progressivement aux abonnés.
La réplication transactionnelle est idéale pour les scénarios serveur à serveur exigeant un débit élevé et une faible latence. Parmi les cas d'utilisation courants, citons l'amélioration de l'évolutivité et de la disponibilité grâce au déchargement des opérations de lecture vers des serveurs abonnés, la prise en charge de l'entreposage et du reporting de données en quasi temps réel, l'intégration des données provenant de plusieurs sites dans un emplacement central et le déchargement du traitement par lots vers des serveurs dédiés. Par exemple, une plateforme de commerce électronique peut utiliser la réplication transactionnelle pour maintenir la synchronisation des données d'inventaire entre des bases de données régionales.
Les avantages de la réplication transactionnelle incluent une faible latence dans la transmission des données, un débit élevé pour les volumes de transactions importants et la possibilité d'effectuer des modifications non répliquées chez les abonnés. Ses inconvénients comprennent une complexité accrue par rapport à la réplication par instantané, l'obligation de définir des clés primaires sur les tables répliquées et le risque d'interruption de la réplication en cas de conflits, tels que des violations de clés primaires chez les abonnés.
3.3 Réplication de fusion
La réplication par fusion est spécialement conçue pour les environnements où les abonnés doivent travailler hors ligne ou avec une connectivité intermittente, puis synchroniser les modifications dès que la connexion est rétablie. Ce type de réplication permet de modifier les données indépendamment chez l'éditeur et les abonnés, en suivant les modifications à l'aide de déclencheurs et de tables de métadonnées, et en fusionnant automatiquement les modifications lors de la synchronisation.
La réplication par fusion est conçue pour les applications mobiles et les environnements de serveurs distribués où des modifications autonomes surviennent. Parmi les cas d'utilisation, on peut citer l'automatisation des forces de vente où les utilisateurs mobiles travaillent hors ligne et synchronisent leurs données ultérieurement, les systèmes de point de vente fonctionnant indépendamment et consolidant périodiquement leurs données, et les applications distribuées où plusieurs sites doivent mettre à jour des données partagées. Par exemple, une chaîne de magasins peut utiliser la réplication par fusion pour que chaque magasin puisse gérer son stock local tout en se synchronisant avec le système d'entrepôt central.
La réplication par fusion présente plusieurs avantages : prise en charge des abonnés autonomes pouvant effectuer des modifications, tolérance aux interruptions de connexion réseau et résolution flexible des conflits. Ses inconvénients incluent une complexité accrue de configuration et de maintenance, une surcharge de performances liée au suivi des métadonnées et des déclencheurs, l’ajout de colonnes d’identifiant unique aux tables et un risque de conflits nécessitant gestion et résolution.
3.4 Réplication pair à pair
La réplication pair à pair repose sur la réplication transactionnelle et permet à plusieurs instances de serveur (trois nœuds ou plus) de fonctionner comme des pairs égaux, chaque nœud jouant simultanément le rôle de diffuseur et d'abonné. Dans cette topologie, tous les nœuds conservent des copies identiques des données et peuvent gérer les opérations de lecture et d'écriture, offrant ainsi un environnement multi-maître véritablement distribué.
La réplication pair à pair est adaptée aux applications nécessitant une montée en charge horizontale des opérations de lecture et une haute disponibilité. Parmi les cas d'utilisation, on peut citer les applications web qui répartissent les requêtes de catalogue sur plusieurs nœuds tout en garantissant la cohérence des données, les scénarios nécessitant une maintenance ou des mises à niveau sans interruption de service grâce à la mise hors ligne individuelle des nœuds, et les applications globales avec des centres de données situés dans différentes régions. Par exemple, une organisation mondiale de support logiciel peut utiliser la réplication pair à pair entre ses bureaux situés dans différents fuseaux horaires afin que chaque site dispose d'un accès local aux données les plus récentes.
Les avantages de la réplication pair à pair incluent une amélioration des performances de lecture grâce à l'extension horizontale, une disponibilité accrue avec plusieurs nœuds actifs et une cohérence des données quasi instantanée. Parmi les inconvénients, on peut citer la nécessité de disposer de l'édition Enterprise, la complexité de la gestion des topologies multi-nœuds, l'exigence d'un schéma et de données identiques sur tous les nœuds et le risque de conflits en cas de partitionnement inadéquat des opérations d'écriture.
3.5 Réplication bidirectionnelle
La réplication bidirectionnelle est une topologie de réplication transactionnelle spécifique, conçue pour les environnements à deux serveurs où ces derniers doivent échanger des modifications. Chaque serveur publie des données et s'abonne aux mêmes données provenant de l'autre serveur, créant ainsi un flux de synchronisation bidirectionnel simple. Bien que la réplication pair à pair puisse également prendre en charge deux nœuds, la réplication bidirectionnelle offre de meilleures performances dans ce cas précis.
La réplication bidirectionnelle convient aux scénarios nécessitant deux serveurs actifs avec des données synchronisées, comme les configurations actif-actif pour une haute disponibilité ou les applications géographiquement distribuées où chaque site requiert un accès en écriture local. La topologie exige une conception applicative rigoureuse afin de partitionner les mises à jour de données et d'éviter les conflits.
Les avantages comprennent des performances optimisées pour les configurations à deux serveurs, une configuration simplifiée par rapport à la réplication pair à pair, une synchronisation quasi instantanée et une surcharge réduite par rapport à la réplication par fusion. Les inconvénients incluent la limitation à deux serveurs, l'absence de mécanisme intégré de résolution des conflits (nécessitant une conception applicative rigoureuse) et la nécessité de stratégies de partitionnement appropriées pour prévenir les conflits.
3.6 Abonnements modifiables
Les abonnements modifiables étendent la réplication transactionnelle pour permettre aux abonnés d'apporter des modifications ponctuelles aux données répliquées, lesquelles sont ensuite propagées à l'éditeur et aux autres abonnés. Contrairement à la réplication par fusion ou aux topologies pair-à-pair conçues pour des mises à jour bidirectionnelles fréquentes, les abonnements modifiables sont destinés aux scénarios où le flux de données principal est unidirectionnel (de l'éditeur vers les abonnés), mais où les abonnés doivent occasionnellement effectuer des corrections ou des mises à jour.
Les abonnements modifiables conviennent aux scénarios où most Les mises à jour sont effectuées chez l'éditeur, mais des mises à jour ponctuelles chez les abonnés sont nécessaires, notamment pour les bureaux de terrain qui consultent principalement les données mais doivent effectuer des corrections ou des mises à jour locales. La topologie exige une planification rigoureuse afin de minimiser les conflits et de garantir la cohérence des données.
Les principaux avantages résident dans la possibilité de limiter les opérations d'écriture chez les abonnés tout en préservant les performances de la réplication transactionnelle. Les inconvénients incluent une complexité accrue, un risque de conflits nécessitant une résolution, une surcharge de performances due au protocole de validation en deux phases en mode de mise à jour immédiate, et l'obligation que toutes les tables répliquées possèdent une clé primaire.
3.7 Comparaison de différents types de réplications
| Type de réplication | Temps de mise à jour | Nombre d'éditeurs | Direction | Utiliser des scénarios |
|---|---|---|---|---|
| Aperçu | Point précis dans le temps | 1 | Une seule direction (Éditeur → Abonnés) | Données de référence peu fréquemment mises à jour (listes de prix, taux de change) |
| Transactionnel | Quasi temps réel | 1 | Une seule direction (Éditeur → Abonnés) | Scénarios à haut débit (gestion des stocks e-commerce, entreposage de données, reporting) |
| aller | Périodique (lorsqu'il est connecté) | 1 | Bidirectionnel (Éditeur ↔ Abonnés) | Applications mobiles, travailleurs hors ligne (automatisation des forces de vente, services sur le terrain) |
| Peer-to-Peer | Quasi temps réel | Plusieurs (3 ou plus) | Bidirectionnel (tous les nœuds) | Déploiements multi-centres de données à l'échelle mondiale (bureaux dans le monde entier avec accès local en lecture-écriture) |
| Bidirectionnelle | Quasi temps réel | 2 | Bidirectionnel (les deux serveurs) | Configurations actives-actives à deux centres de données (haute disponibilité à double site) |
| Abonnements modifiables | Quasi temps réel | 1 | Principalement dans un seul sens (mises à jour occasionnelles dans l'autre sens) | Succursales chargées principalement de la lecture mais occasionnellement de la mise à jour (corrections locales) |
4. Configuration SQL Server réplication
4.1 Prérequis et exigences
4.1.1 Configuration logicielle requise
SQL Server La réplication nécessite une compatibilité SQL Server Les versions doivent être identiques pour tous les participants de la topologie. La version du distributeur doit être égale ou supérieure à celle de l'éditeur, et la version de l'abonné peut être à deux versions près de celle de l'éditeur. Par exemple, une version de l'abonné doit être supérieure ou égale à celle de l'éditeur. SQL Server L'éditeur de 2016 peut répliquer vers SQL Server Abonnés de 2012, 2014, 2016, 2017 ou 2019.
4.1.2 Exigences d'autorisation
La configuration de la réplication requiert des autorisations spécifiques à chaque niveau. Les membres disposant du rôle serveur fixe sysadmin peuvent effectuer toutes les tâches de configuration de la réplication. Pour des autorisations plus précises, les utilisateurs doivent être membres du rôle de base de données db_owner pour les bases de données de publication et d'abonnement.
4.2 Étape 1 : Configurer la distribution
Configurer la distribution est la première étape de la mise en place SQL Server réplication.
Pour configurer la distribution à l'aide de SQL Server Atelier de gestion :
- Connectez-vous à SQL Server exemple dans SQL Server Atelier de gestion.
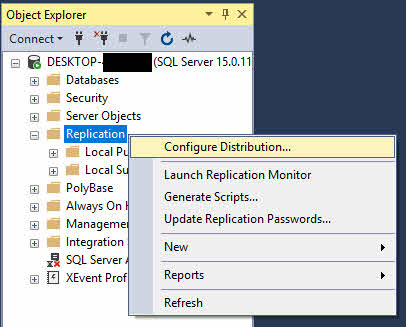
- Dans l'Explorateur d'objets, cliquez avec le bouton droit sur réplication dossier et sélectionnez Configurer la distribution.

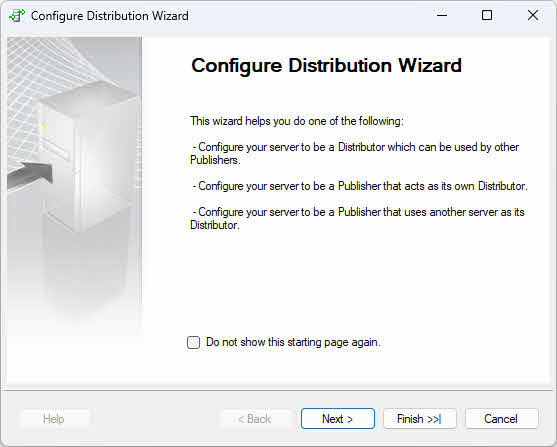
- Dans l'assistant de configuration de la distribution, cliquez Suivant sur la page d'accueil.

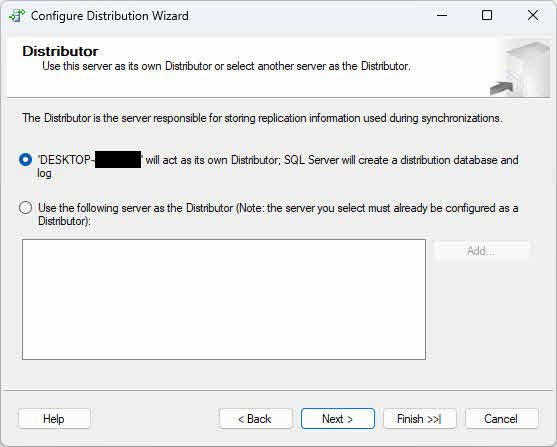
- Sur le Distributeurs Sur cette page, choisissez l'une des options suivantes en fonction de vos exigences de topologie :
- Distributeur local: Sélectionnez « ServerName agira comme son propre distributeur ; SQL Server Cette option créera une base de données de distribution et un journal si vous souhaitez que l'éditeur et le distributeur s'exécutent sur la même instance (l'instance actuelle). Cette configuration est plus simple à mettre en place et convient aux environnements de petite taille ou lorsque la latence réseau entre l'éditeur et le distributeur risque de poser problème.
- Distributeur à distanceSélectionnez « Utiliser le serveur suivant comme distributeur » et cliquez sur Ajouter Spécifiez un serveur de distribution distant si vous souhaitez décharger le traitement de la distribution sur une instance distincte. Cette configuration améliore les performances en cas de volumes de réplication élevés en répartissant la charge de travail sur plusieurs serveurs. Vous devrez fournir le nom du serveur de distribution distant et un mot de passe que l'éditeur utilisera pour s'y connecter.
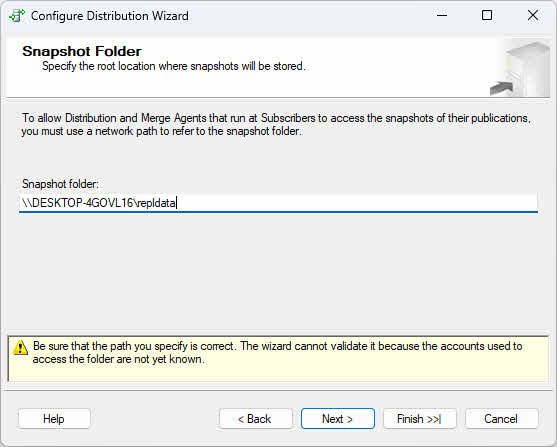
- Cliquez à nouveau sur Suivant Pour spécifier l'emplacement du dossier de snapshots, utilisez un chemin UNC (tel que \\nom_serveur\partage\dossier) plutôt qu'un chemin local afin de garantir l'accessibilité sur le réseau.
- Sur le Base de données de distribution Sur cette page, acceptez le nom par défaut de la base de données de distribution (généralement « distribution ») ou spécifiez un nom personnalisé, puis configurez l’emplacement des fichiers de données et de journalisation.
- Sur le Éditeurs Sur cette page, vérifiez que le serveur actuel est configuré comme éditeur. Si vous le configurez comme distributeur, vous pouvez ajouter d'autres éditeurs qui utiliseront ce distributeur.

- Examinez les actions de l'assistant et cliquez Finition configurer la distribution.
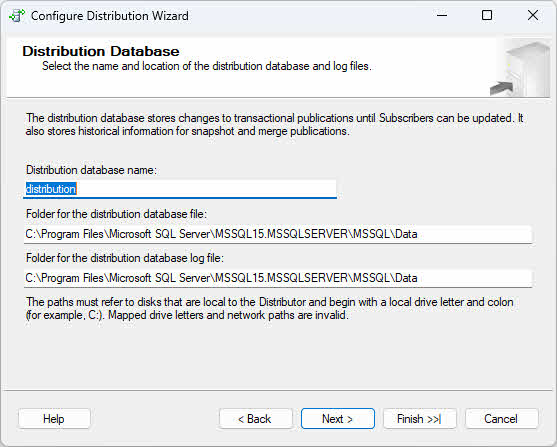
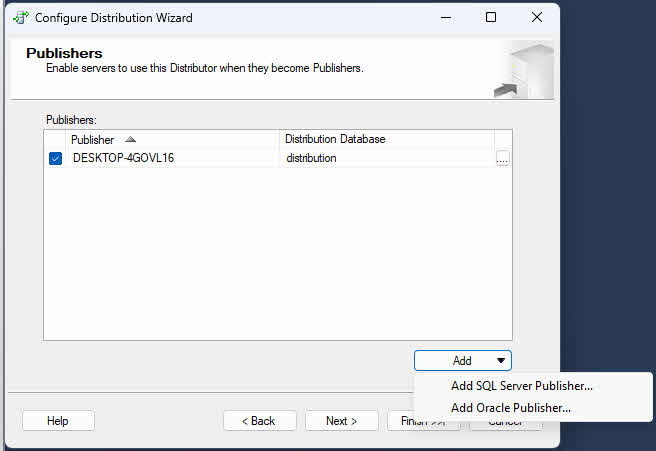
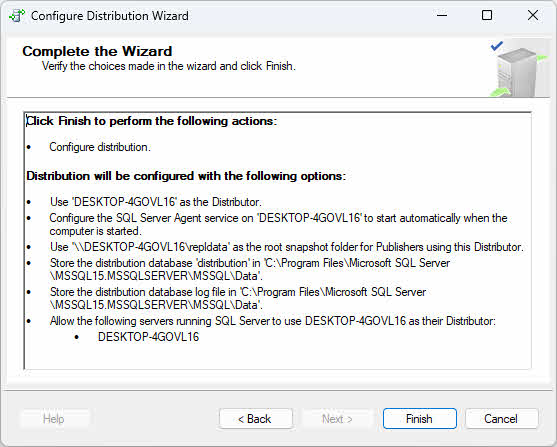
4.3 Étape 2 : Créer une publication
Après avoir configuré la distribution, l'étape suivante consiste à créer une publication qui définit quels objets de données seront répliqués auprès des abonnés.
Pour créer une publication en utilisant SQL Server Atelier de gestion :
- Dans l'explorateur d'objets, développez le réplication dossier.
- Faites un clic droit Publications locales et sélectionnez Nouvelle publication.
- Le nouvel assistant de publicationtarts; cliquez Suivant sur la page d'accueil.
- Sélectionnez la base de données que vous souhaitez publier dans la Base de données de publications page. Cela active automatiquement la publication sur la base de données sélectionnée.
- Sur le Type de publication page, sélectionnez le type de réplication : Publication instantanée, Publication transactionnelle, Publication entre pairs, Fusionner la publication.
- Sur le Articles page, développez la Tableaux Nœud et sélectionnez les tables à inclure comme articles.
- Extension facultative Procédures stockées, Vues, ou d'autres types d'objets pour inclure des articles supplémentaires.
- Cliquez à nouveau sur Propriétés de l'article pour configurer le filtrage ou d'autres paramètres spécifiques à l'article.
- Sur le Filtrer les lignes du tableau page, ajoutez des filtres de ligne si nécessaire.
- Sur le Agent instantané Sur cette page, choisissez le moment de la création de l'instantané : immédiatement, à une heure précise ou selon une planification.
- Sur le Agent de sécurité page, spécifiez le contexte de sécurité pour l'agent Snapshot.
- Sur le Actions du magicien page, sélectionnez Créer la publication.
- Indiquez le nom de la publication et cliquez Finition.
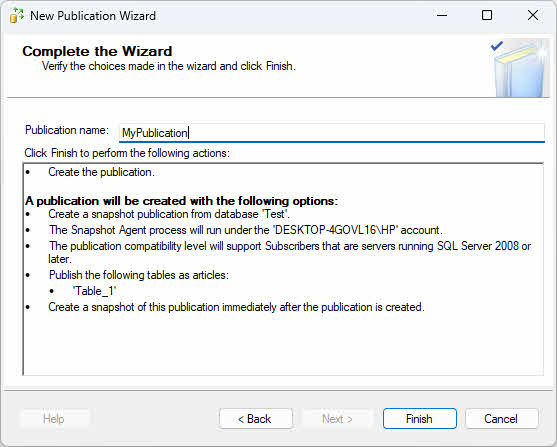
4.4 Étape 3 : Créer un abonnement
Après avoir créé une publication, l'étape suivante consiste à créer des abonnements qui relient la publication aux bases de données d'abonnés.
Les abonnements peuvent être de type « push » (gérés par le distributeur) ou « pull » (gérés par l’abonné). La principale différence réside dans le lieu de création de l’abonnement et l’emplacement de l’agent sélectionné, ce qui détermine le mode de gestion de l’abonnement (push ou pull).
Pour l'abonnement aux notifications push (géré par le distributeur) :
- Sur le éditeur serveur, développer réplication -> Publications locales.
- Cliquez avec le bouton droit sur la publication et sélectionnez Nouveaux abonnements.
Pour l'abonnement Pull (géré par l'abonné) :
- Sur le abonné serveur, développer réplication, clic-droit Abonnements locaux, et sélectionnez Nouveaux abonnements.
- Sur le Publication page, cliquez sur Trouvez SQL Server Publisher et se connecter au serveur de l'éditeur.
Étapes communes de l'assistant pour les deux types d'abonnement :
- Dans l'assistant de nouvel abonnement, cliquez Suivant sur la page d'accueil.
- Sélectionnez la publication et cliquez Suivant.
- Sur le Localisation de l'agent de distribution page, choisissez l'emplacement de l'agent :
- Abonnement pushSélectionnez « Exécuter tous les agents sur le distributeur » – le distributeur transmettra les modifications aux abonnés.
- Abonnement PullSélectionnez « Exécuter chaque agent chez son abonné » – chaque abonné récupérera les modifications auprès du distributeur.
- Sur le Abonnés page, sélectionnez les serveurs d'abonnés existants ou cliquez Ajouter un abonné pour en ajouter de nouveaux.
- Pour chaque abonné, sélectionnez la base de données de destination ou créez une nouvelle base de données. À noter: La base de données des abonnés doit être différente de la base de données de l'éditeur, même si elle utilise la même technologie. SQL Server exemple.
- Sur le Agent de distribution Sécurité Sur la page, cliquez sur le bouton Propriétés de chaque abonnement pour configurer le contexte de sécurité.
- Sur le Calendrier de synchronisation Sur cette page, choisissez entre la synchronisation continue et la synchronisation planifiée.
- Sur le Initialiser les abonnements page, sélectionnez Immédiatement pour initialiser à la fin de l'assistant ou Au début de la synchronisation.
- Examinez les actions de l'assistant et cliquez Finition.
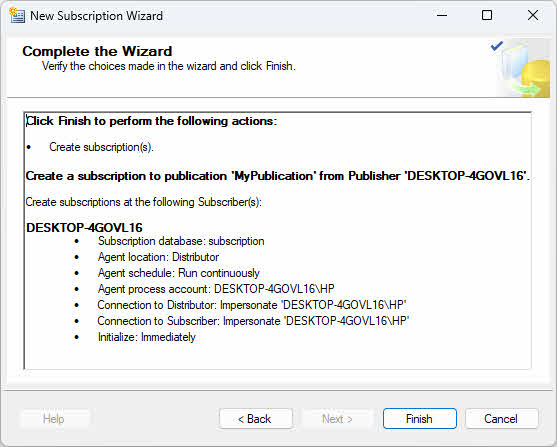
5. Surveillance et gestion SQL Server réplication
5.1 Surveillance de la réplication avec Replication Monitor
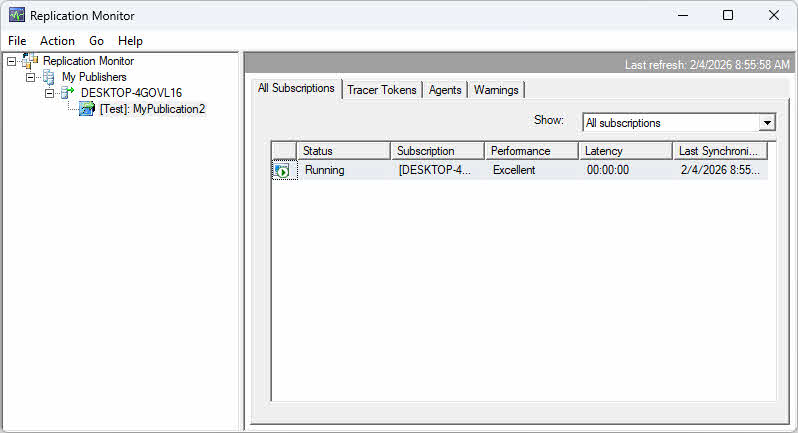
Pour lancer Replication Monitor :
- In SQL Server Studio de gestion, développer réplication dans l'explorateur d'objets.
- Faites un clic droit réplication et sélectionnez Moniteur de réplication de lancement.
- Si aucun éditeur n'est enregistré, cliquez Ajouter un éditeur dans le volet de gauche.
- Choisissez Ajouter SQL Server Publisher et se connecter au serveur de l'éditeur.
- L'éditeur apparaît dans le volet de gauche avec des nœuds extensibles pour les publications et les abonnements.
5.2 Suivi des performances
5.2.1 Latence du moniteur
La latence de réplication correspond au délai entre une modification survenant chez l'éditeur et son application chez l'abonné. Surveillez cette latence pour garantir que la fraîcheur des données réponde aux exigences métier.
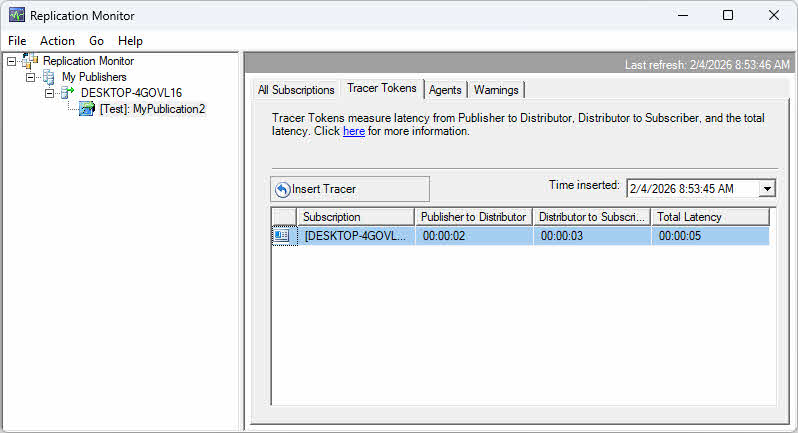
Utilisez le Moniteur de réplication pour consulter les métriques de latence dans l'onglet « Tous les abonnements ». La colonne « Latence » indique la latence moyenne en secondes. Pour la réplication transactionnelle, les jetons de suivi permettent d'obtenir des mesures de latence précises en insérant des transactions marqueurs qui sont suivies tout au long du pipeline de réplication.
Pour utiliser les jetons de traçage :
- Dans le Moniteur de réplication, sélectionnez une publication transactionnelle.
- Cliquez sur Jetons de traçage languette.
- Cliquez à nouveau sur Insérer le traceur injecter une transaction de marqueur.
- Surveillez le jeton tout au long de son parcours, de l'éditeur au distributeur puis à l'abonné.
- Consultez le temps nécessaire pour chaque segment afin d'identifier les goulots d'étranglement.
5.2.2 Surveillance du débit
Le débit mesure le volume de données répliquées au fil du temps, généralement exprimé en transactions par seconde ou en commandes par seconde. Surveillez le débit pour vous assurer que la réplication peut suivre le rythme de l'activité de l'éditeur.
Bien que Replication Monitor fournisse un état de synchronisation de base, le taux de distribution et les indicateurs de débit détaillés ne sont pas visibles dans l'interface graphique. Utilisez des requêtes T-SQL sur la base de données de distribution pour surveiller le débit :
USE distribution
GO
-- Direct join to avoid subquery
SELECT TOP 20
h.time AS [Time],
a.name AS [Agent Name],
h.runstatus AS [Status],
h.delivered_transactions AS [Delivered Transactions],
h.delivered_commands AS [Delivered Commands],
h.delivery_rate AS [Delivery Rate (commands/sec)],
h.delivery_latency AS [Delivery Latency (ms)],
h.comments AS [Comments]
FROM MSdistribution_history h
JOIN MSdistribution_agents a ON h.agent_id = a.id
WHERE a.name LIKE '%MyPublication2%'
AND h.runstatus IN (2, 3, 4, 6)
ORDER BY h.time DESC
GO
Codes d'état : 1 = Start = 2 = En cours, 3 = Réussi, 4 = Inactif, 5 = Nouvelle tentative, 6 = Échec. Comparez le taux de distribution aux taux de transactions de l'éditeur pour identifier les situations où la réplication prend du retard. Compteurs de performance dans Windows Performance Monitor Fournir des indicateurs de débit supplémentaires pour chaque agent de réplication.
5.2.3 Identifier les goulots d'étranglement
Des goulots d'étranglement lors de la réplication peuvent survenir à différents niveaux de la topologie. Au niveau du serveur de publication, un temps de génération d'instantanés excessif ou des retards de l'agent de lecture des journaux peuvent indiquer des contraintes de ressources. Surveillez l'utilisation du processeur, de la mémoire et des E/S disque sur le serveur de publication pendant les opérations de réplication.
Chez le distributeur, vérifiez l'accumulation des transactions dans la base de données de distribution. Un grand nombre de commandes non distribuées indique que le distributeur ne parvient pas à suivre le rythme des livraisons. Surveillez les ressources du serveur du distributeur et envisagez l'utilisation d'un distributeur distant dédié pour les volumes importants.
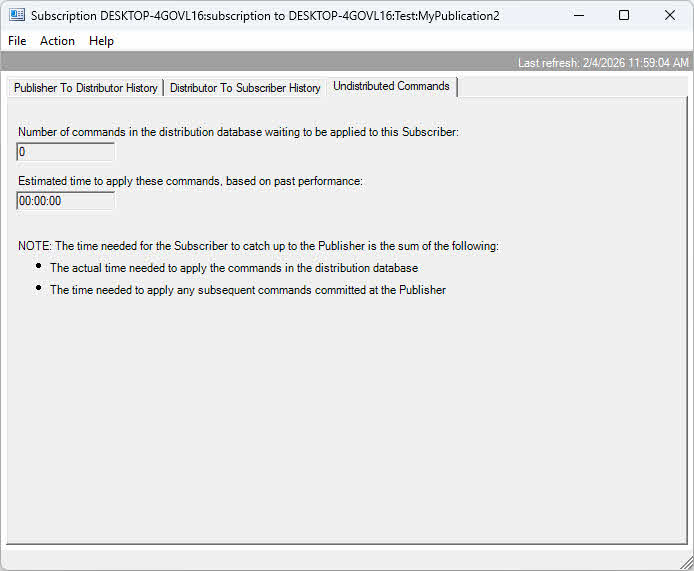
Chez l'abonné, la lenteur de l'application des modifications peut être due à des ressources insuffisantes, à des index manquants ou à des contraintes ralentissant les opérations d'insertion. Surveillez l'utilisation des ressources et les performances des requêtes chez l'abonné lorsque l'agent de distribution est en cours d'exécution. Les limitations de bande passante réseau entre les composants peuvent également engendrer des goulots d'étranglement, notamment pour les volumes de données importants.
5.3 Gestion des agents de réplication
5.3.1 Start et agents d'arrêt
À starou arrêter un agent de réplication :
- In SQL Server Studio de gestion, développer SQL Server Agent -> Emplois.
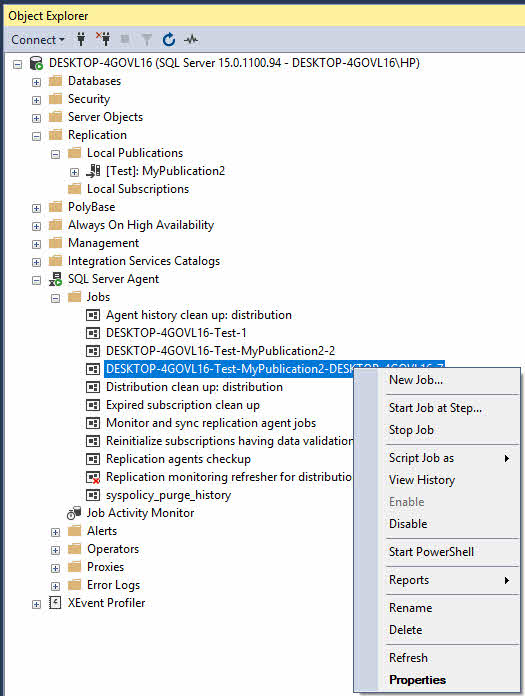
- Localisez la tâche de l'agent de réplication (les noms incluent généralement les informations de publication et d'abonné).
- Cliquez avec le bouton droit sur la tâche et sélectionnez Start Emploi or Arrêter le travail.
5.3.2 Configurer les profils d'agent
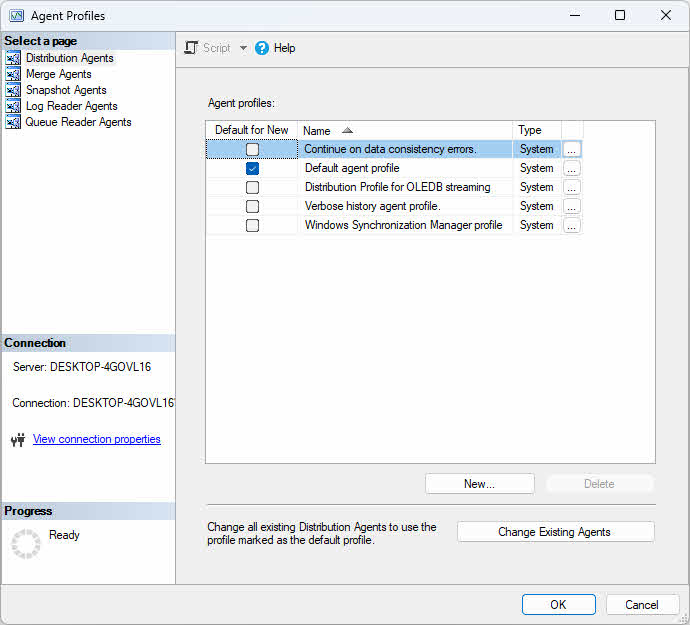
Les profils d'agent contiennent des ensembles de paramètres qui contrôlent le comportement de l'agent. SQL Server Il propose des profils par défaut optimisés pour les scénarios courants, et vous pouvez créer des profils personnalisés pour des besoins spécifiques.
Pour modifier les profils des agents :
- Dans l'explorateur d'objets, développez réplication.
- Faites un clic droit réplication et sélectionnez Propriétés du distributeur.
- Cliquez sur Paramètres par défaut du profil .
- Sélectionnez un type d'agent (Instantané, Lecteur de journal, Distribution ou Fusion) dans la liste déroulante.
- Sélectionnez un profil et cliquez Propriétés pour afficher les valeurs des paramètres.
- Cliquez à nouveau sur Nouveau profile créer un profil personnalisé à partir d'un profil existant.
- Modifiez les paramètres selon vos besoins et cliquez OK.
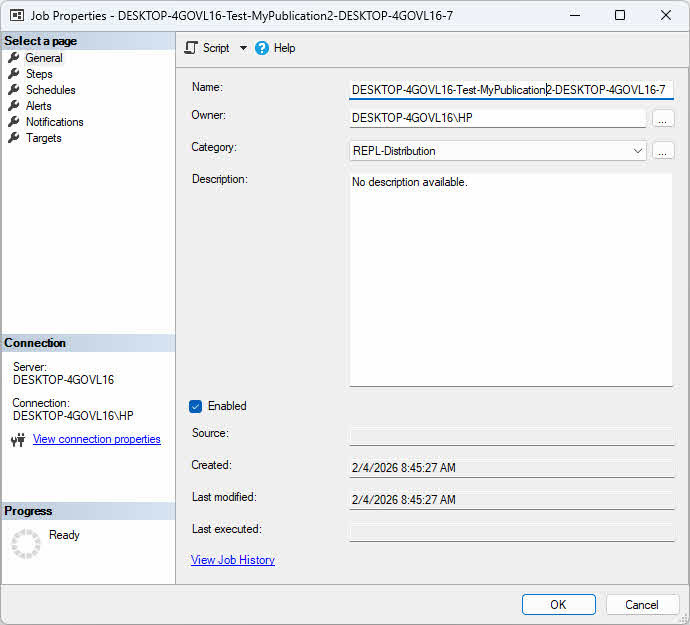
Attribuez un profil à un agent en modifiant les propriétés de l'abonnement et en sélectionnant le profil souhaité dans le menu déroulant Profil de l'agent.
5.3.3 Paramètres et réglages de l'agent
Les paramètres de l'agent permettent d'optimiser ses performances et son comportement. Les principaux paramètres de l'agent de distribution incluent CommitBatchSize (nombre de transactions appliquées par validation), CommitBatchThreshold (nombre de commandes avant validation), SubscriptionStreams (connexions parallèles pour une distribution plus rapide) et QueryTimeout (délai d'expiration des commandes).
Pour l'agent de lecture des journaux, les paramètres importants sont ReadBatchSize (nombre de transactions lues par analyse), ReadBatchThreshold (nombre de commandes avant la livraison) et PollingInterval (délai entre les analyses de journaux). Ajustez ces paramètres en fonction du volume de transactions et des exigences de latence.
5.4 Considérations relatives à la sauvegarde et à la restauration
La sauvegarde des bases de données impliquées dans la réplication requiert une attention particulière. Pour la base de données de publication, des sauvegardes complètes et régulières des journaux de transactions sont indispensables. Lors de la sauvegarde de bases de données en réplication transactionnelle, utilisez l'option WITH REPLICATION pour prendre en charge la réplication. Sauvegardez régulièrement la base de données de distribution afin de préserver la configuration de réplication.
Lors de la restauration d'une base de données d'éditeur sur le même serveur et avec le même nom, utilisez l'option WITH KEEP_REPLICATION pour préserver l'état de la réplication. Cette option garantit que les transactions non encore traitées par l'agent de lecture des journaux restent marquées pour la réplication, permettant ainsi à celle-ci de se poursuivre automatiquement sans réinitialisation des abonnements.
Dans les scénarios de reprise après sinistre où les sauvegardes sont indisponibles, corrompues ou lorsque les fichiers de base de données sont endommagés, des outils de récupération spécialisés peuvent être nécessaires. DataNumen SQL Recovery peut extraire des données à partir de fichiers MDF et NDF corrompus ou inaccessibles, offrant une solution de dernier recours lorsque les procédures de restauration standard échouent.
Pour plus de détails sur SQL Server sauvegarde, consultez notre guide complet.
6. Foire aux questions (FAQ)
Q : Quelle est la différence entre la réplication par instantané et la réplication transactionnelle ?
A : La réplication par instantané prend une copie complète des données à un moment précis et l'applique à l'abonné, ce qui convient aux données qui changent rarement. La réplication transactionnelletarts effectue une capture d'écran initiale, puis réplique en continu les transactions individuelles au fur et à mesure qu'elles se produisent, assurant ainsi une synchronisation quasi temps réel pour les données qui évoluent fréquemment.
Q : Puis-je répliquer entre différents SQL Server versions?
Un: oui, SQL Server La réplication prend en charge la compatibilité des versions dans une plage limitée. La version du distributeur doit être égale ou supérieure à celle de l'éditeur, et la version de l'abonné peut être comprise entre deux versions de celle de l'éditeur. Par exemple, si l'éditeur est SQL Server En 2016, l'abonné peut être SQL Server 2012, 2014, 2016, 2017 ou 2019.
Q : Comment gérer les conflits lors de la réplication par fusion ?
A: La réplication par fusion intègre des mécanismes de détection et de résolution des conflits. Vous pouvez configurer les résolveurs de conflits au niveau de l'article, en choisissant parmi les résolveurs intégrés ou en implémentant des résolveurs personnalisés. Les conflits sont généralement résolus selon des méthodes basées sur la priorité ou l'horodatage, avec la possibilité de les consigner pour une vérification manuelle.
Q : Quels sont les impacts de la réplication sur les performances ?
A : La réplication a un impact sur les performances de plusieurs manières : le serveur de publication subit une surcharge liée au suivi des modifications et à la génération d’instantanés, le serveur de distribution utilise des ressources pour stocker et transférer les transactions, et la bande passante réseau est consommée lors du transfert de données. Cet impact varie selon le type de réplication : la réplication par instantané provoque des pics de performance périodiques importants, tandis que la réplication transactionnelle maintient une charge plus stable et continue.
Q : Comment sécuriser ma topologie de réplication ?
A : Sécurisez votre topologie de réplication en appliquant plusieurs bonnes pratiques : utilisez l’authentification Windows ou une authentification forte. SQL Server Authentification, chiffrement des connexions à l'aide de TLS, sécurisation du dossier de snapshots avec les mesures appropriées NTFS autorisations, configurez la liste d'accès aux publications (PAL) pour contrôler l'accès, utilisez des comptes de service distincts avec les autorisations minimales requises pour chaque agent de réplication et auditez régulièrement les paramètres de sécurité de la réplication.
Q : Puis-je répliquer vers Azure SQL Database ?
R : Oui, vous pouvez répliquer vers Azure SQL Database en utilisant la réplication transactionnelle avec une infrastructure locale. SQL Server Azure SQL Database peut servir d'éditeur et de distributeur, ou d'instance gérée Azure SQL. Elle peut cependant servir d'abonné, mais pas d'éditeur ni de distributeur. La réplication de fusion et la réplication pair à pair ne sont pas prises en charge par Azure SQL Database.
Q : Comment puis-je surveiller le délai de réplication ?
A : Surveillez le délai de réplication à l'aide de Replication Monitor dans SQL Server Management Studio affiche les indicateurs de latence pour chaque abonnement. Vous pouvez également interroger les tables de la base de données de distribution telles que MSdistribution_history et MSrepl_commands, utiliser les compteurs de performance spécifiques aux agents de réplication ou configurer des alertes basées sur des seuils de latence afin de détecter et de corriger proactivement les retards de synchronisation.
Q : Que se passe-t-il lorsqu'un abonné est hors ligne ?
A : Lorsqu'un abonné est hors ligne, le comportement dépend du type de réplication. Pour la réplication transactionnelle, les transactions s'accumulent dans la base de données de distribution jusqu'à ce que l'abonné se reconnecte, puis la synchronisation reprend. Pour la réplication de fusion, les modifications sont suivies des deux côtés et fusionnées lorsque la connectivité est rétablie. Le paramètre de période de rétention détermine la durée de conservation des données avant leur réinitialisation.
Q : Comment puis-je ajouter de nouveaux articles à une publication existante ?
A: Pour ajouter de nouveaux articles à une publication existante, utilisez SQL Server Utilisez Management Studio pour modifier les propriétés de la publication et sélectionner des objets supplémentaires, ou utilisez la procédure stockée sp_addarticle. Après avoir ajouté des articles, générez un nouvel instantané et réinitialisez tous les abonnements pour garantir la réception des nouveaux articles par les abonnés. Selon les paramètres de publication, certaines modifications peuvent nécessiter une réinitialisation des abonnements.
Q : Comment supprimer la réplication d'une base de données ?
A : Supprimez la réplication d'une base de données en commençant par supprimer tous les abonnements à l'aide de sp_dropsubscription, puis la publication avec sp_droppublication, et enfin en désactivant la publication sur la base de données à l'aide de sp_replicationdboption. Si le serveur est un distributeur, désactivez la distribution à l'aide de sp_dropdistributor. Sauvegardez toujours les bases de données avant de supprimer la configuration de réplication.
Q: Quelle est la différence entre SQL Server Réplication et groupes de disponibilité AlwaysOn ?
A : La réplication est une solution de distribution et d'intégration de données qui fonctionne au niveau de l'objet, tandis que Groupes de disponibilité toujours activés est une solution de haute disponibilité et de reprise après sinistre qui fonctionne au niveau de la base de données.
7. Conclusion
SQL Server La réplication offre un cadre robuste pour la distribution et la synchronisation des données entre plusieurs bases de données et emplacements. Cette technologie prend en charge divers scénarios grâce à différents types de réplication.
Le choix de la stratégie de réplication appropriée dépend de vos besoins spécifiques. Prenez en compte la fréquence des modifications de données, les exigences de latence, la nécessité pour les abonnés d'effectuer des mises à jour, les caractéristiques du réseau et les besoins d'autonomie des abonnés. La réplication par instantané est idéale pour les données de référence peu fréquemment modifiées, pour lesquelles la latence n'est pas critique. La réplication transactionnelle convient aux scénarios à volume élevé exigeant une faible latence et un flux de données principalement unidirectionnel.
Optez pour la réplication par fusion lorsque les abonnés ont besoin d'un fonctionnement autonome avec des capacités hors ligne et une synchronisation bidirectionnelle. Mettez en œuvre la réplication pair à pair pour répartir la charge des opérations de lecture sur plusieurs nœuds actifs avec une cohérence quasi temps réel. Envisagez des approches hybrides combinant plusieurs types de réplication pour les scénarios complexes aux exigences diverses.
Références
- Document officiel de Microsoft : SQL Server réplication
- Document officiel Microsoft : Types de réplication
- Document officiel Microsoft : Réplication transactionnelle pair à pair
À propos de l’auteur
Yuan Sheng est un administrateur de base de données senior (DBA) avec plus de 10 ans d'expérience dans SQL Server Environnements et gestion de bases de données d'entreprise. Il a résolu avec succès des centaines de scénarios de récupération de bases de données dans des organisations du secteur financier, de la santé et de l'industrie manufacturière.
Yuan se spécialise dans SQL Server Récupération de bases de données, solutions de haute disponibilité et optimisation des performances. Sa vaste expérience pratique comprend la gestion de bases de données de plusieurs téraoctets, la mise en œuvre de groupes de disponibilité permanente (AAL) et le développement de stratégies automatisées de sauvegarde et de restauration pour les systèmes d'entreprise critiques.
Grâce à son expertise technique et à son approche pratique, Yuan se concentre sur la création de guides complets qui aident les administrateurs de bases de données et les professionnels de l'informatique à résoudre des problèmes complexes. SQL Server défis efficacement. Il se tient au courant des dernières SQL Server les versions et les technologies de base de données en constante évolution de Microsoft, testant régulièrement des scénarios de récupération pour garantir que ses recommandations reflètent les meilleures pratiques du monde réel.
Vous avez des questions sur SQL Server Besoin d'aide pour la récupération de votre base de données ? Yuan vous accueille. commentaires et suggestions pour améliorer ces ressources techniques.