1. Présentation de SQL Server Analyseur de performances
1.1 Qu'est-ce que SQL Server Moniteur de performances ?
SQL Server Le moniteur de performances est le processus de suivi, d'analyse et de gestion des performances et de la santé de votre SQL Server Bases de données. Il s'agit de collecter et d'interpréter des données sur divers aspects de votre système de base de données afin d'assurer des performances optimales, de prévenir les problèmes et de maintenir la santé de la base de données.

La surveillance des performances englobe le suivi des temps d'exécution des requêtes, de l'utilisation des ressources, des performances des index, des blocages et des interblocages, ainsi que des schémas de croissance des bases de données. Cette surveillance continue permet aux administrateurs d'identifier les problèmes potentiels avant qu'ils n'impactent les utilisateurs ou les opérations métier.
1.2 Principaux avantages du suivi des performances
Efficace à partir de SQL Server Le moniteur de performances offre plusieurs avantages essentiels :
- Détection proactive des problèmes : Identifier et résoudre les problèmes potentiels avant qu'ils n'affectent les utilisateurs ou les opérations commerciales
- Optimisation des performances: Identifiez les goulots d'étranglement et les inefficacités pour améliorer les performances globales de la base de données
- Planification des capacités : Prévoir les besoins en ressources et planifier la croissance future en fonction des données historiques
- Conformité et sécurité : Assurer le respect des exigences réglementaires et détecter les activités suspectes
1.3 Défis de performance courants
Sans un système de surveillance des performances de la base de données SQL approprié, les organisations sont confrontées à plusieurs risques :
- Temps d'arrêt inattendu qui perturbe les opérations commerciales
- Faibles performances des applications affectant l'expérience utilisateur
- Perte ou corruption de données
- Utilisation inefficace des ressources conduisant à des c inutilesosts
- Utilisateurs frustrés et perte de revenus potentielle
Selon une étude IDC de 2023, 65 % des problèmes de performances des bases de données proviennent de mauvaises pratiques de surveillance ou d’optimisation.
2. Comprendre le Moniteur de performances Windows (PerfMon)
2.1 Qu'est-ce que le Moniteur de performances Windows ?
Le Moniteur de performances Windows (PerfMon) est un outil Windows intégré qui surveille les ressources système et les performances des applications. SQL Server administrateurs, PerfMon fournit des informations précieuses sur le système d'exploitation et SQL Server métriques, ce qui le rend essentiel pour une analyse complète des performances.
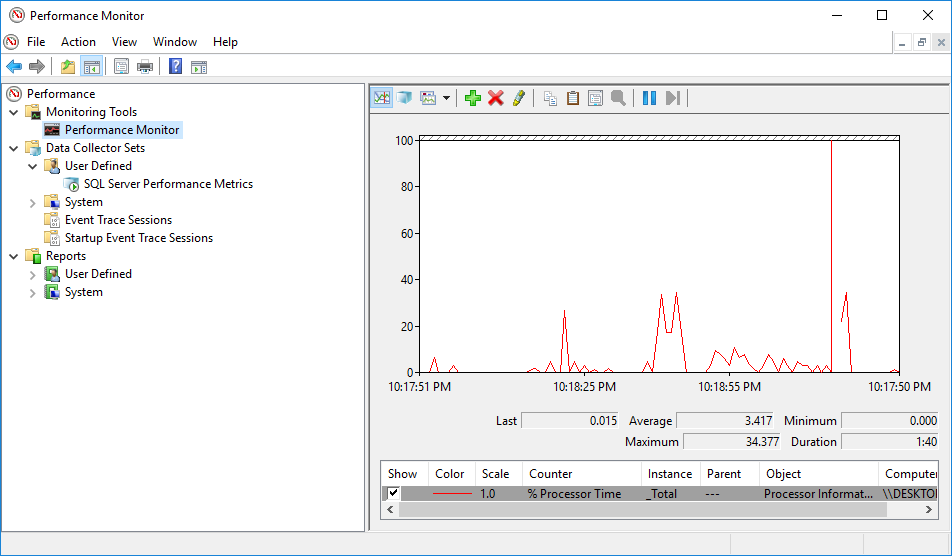
PerfMon mesure les statistiques de performance à intervalles réguliers et les enregistre dans des fichiers pour analyse ultérieure. Les administrateurs de base de données peuvent sélectionner l'intervalle de temps, le format de fichier et les statistiques à surveiller. L'outil n'est pas SQL Server-spécifique : les administrateurs système l'utilisent pour surveiller Windows lui-même, Exchange, les serveurs de fichiers et toute application pouvant rencontrer des goulots d'étranglement.
2.2 Lancement de Performance Monitor
Vous pouvez lancer le Moniteur de performances à l’aide de plusieurs méthodes :
- Cliquez à nouveau sur Commencer, Le type perfmon dans la zone de recherche, cliquez sur « Performand Monitor » dans le résultat de la recherche :

- Presse Windows + R, Le type perfmonet appuyez sur Entrer

- Accédez à Panneau de configuration -> Système et sécurité -> Outils d'administration -> Analyseur de performances

3. Essentiel SQL Server Compteurs de performance
3.1 Compteurs de performances de mémoire
Les compteurs de mémoire sont essentiels pour la surveillance SQL Server performances car elles indiquent si votre base de données dispose de ressources mémoire suffisantes.
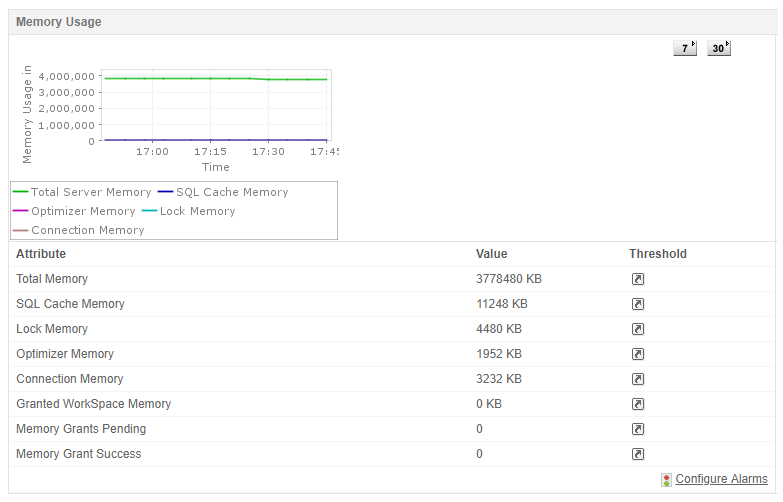
Mo disponibles
Ce compteur indique la quantité de mémoire physique immédiatement disponible pour l'allocation. Il doit rester relativement constant et idéalement ne pas descendre en dessous de 4 096 Mo. Des valeurs faibles peuvent indiquer que SQL ServerLe paramètre de mémoire maximale est laissé par défaut, ou nonSQL Server les applications consomment de la mémoire.
Espérance de vie des pages
L'espérance de vie d'une page mesure la durée (en secondes) pendant laquelle une page reste dans le pool de mémoire tampon sans être référencée. Une valeur normale est de 300 secondes ou plus. Des valeurs inférieures indiquent une pression sur la mémoire et une rotation excessive de la mémoire tampon, réduisant ainsi l'efficacité du cache.
Taux de réussite du cache tampon
Ce compteur indique le pourcentage de requêtes de données traitées via le cache tampon SQL (mémoire) plutôt que via la lecture sur disque. Il atteint ou dépasse généralement 99 %. Des valeurs inférieures suggèrent que SQL Server a besoin de plus de mémoire ou est encore en train de chauffer après une réinstallationtart.
Subventions de mémoire en attente
Ceci montre le nombre de processus en attente de mémoire dans SQL ServerDans des conditions normales, cette valeur doit toujours être égale à 0. Des valeurs plus élevées indiquent une allocation de mémoire insuffisante pour SQL Server.
Tarobtenir la mémoire du serveur par rapport à la mémoire totale du serveur
Tarobtenir la mémoire du serveur indique la quantité de mémoire idéale SQL Server veut utiliser. La mémoire totale du serveur indique ce que SQL Server Actuellement utilisé. Le rapport entre ces valeurs devrait être d'environ 1. Des différences significatives peuvent indiquer une pression sur la mémoire ou une mémoire disponible insuffisante.
3.2 Compteurs de performances du processeur
Les compteurs CPU aident à identifier les goulots d'étranglement du processeur et à comprendre comment SQL Server utilise des ressources informatiques.
% Temps processeur
Ce paramètre mesure le pourcentage de temps écoulé que le processeur consacre à l'exécution des threads actifs. Sur les serveurs actifs, ces valeurs peuvent atteindre 100 %, mais une utilisation prolongée supérieure à 70-75 % indique généralement des problèmes de performances pour les utilisateurs. Des index manquants ou inadéquats entraînent souvent une utilisation intensive du processeur.
% de temps privilégié
Le temps processeur est réparti entre les traitements en mode utilisateur et en mode privilégié (noyau). Tous les accès disque et les E/S s'effectuent en mode noyau. Si ce compteur dépasse 25 %, le système effectue probablement trop d'E/S. Les valeurs normales se situent entre 5 et 10 %.
Longueur de la file d'attente du processeur
Ce compteur affiche les threads en attente de ressources CPU. Les valeurs sont constamment supérieures à 1 (sauf pendant SQL Server compression de sauvegarde) indiquent une pression sur le processeur. Cela signifie souvent que d'autres applications sont installées sur le SQL Server machine, ce qui viole les bonnes pratiques.
Changements de contexte/sec
Cette mesure mesure la fréquence à laquelle le processeur bascule entre les threads. Un changement de contexte excessif peut impacter les performances et indiquer une charge système élevée.
3.3 Compteurs de performances d'E/S de disque
Les compteurs de disque sont essentiels pour la surveillance des performances SQL, car les E/S de disque deviennent souvent le principal goulot d'étranglement dans les systèmes de base de données.
% Temps disque
Cet indicateur enregistre le pourcentage de temps pendant lequel le disque a été occupé par des opérations de lecture/écriture. Des valeurs constamment supérieures à 85 % indiquent un goulot d'étranglement des E/S. Le disque étant beaucoup plus lent que la mémoire, la réduction de cette mesure améliore les performances.
Durée moyenne du disque en secondes (lecture et écriture)
Ces compteurs mesurent le temps moyen (en secondes) des opérations de lecture et d'écriture. Si la valeur moyenne dépasse 10 à 20 ms, le disque met trop de temps à traiter les données. Les lecteurs de journaux de transactions nécessitent des performances d'écriture particulièrement élevées.
Longueur de la file d'attente du disque
Ceci indique les requêtes de lecture/écriture en attente sur le disque. Des valeurs constamment supérieures à 2 (ou 2 par disque pour les matrices RAID) indiquent que le disque ne peut pas gérer les requêtes d'E/S.
Octets de disque/sec
Ce module surveille le débit de transfert de données vers/depuis le disque. Si ce débit dépasse la capacité nominale du disque, les données commencent à s'accumuler, comme l'indique l'augmentation de la longueur de la file d'attente du disque.
Transferts de disque/sec
Cela suit le nombre d'opérations de lecture/écriture effectuées sur le disque. SQL Server L'accès aux données est généralement aléatoire, ce qui ralentit le processus en raison du mouvement de la tête du lecteur. Assurez-vous que cette valeur reste inférieure à la capacité maximale de votre lecteur de disque (généralement 100/s pour les lecteurs standard).
3.4 SQL Server Compteurs spécifiques
3.4.1 Compteurs du gestionnaire de tampons
Surveiller les compteurs du gestionnaire de tampons SQL ServerOpérations de mémoire tampon de :
- Lectures de pages/sec : Nombre cumulé de lectures de pages de base de données physiques
- Écritures de pages/sec : Nombre cumulé d'écritures de pages de base de données physiques
- Écritures paresseuses/sec : Nombre de tampons écrits par l'écrivain paresseux pour libérer de la mémoire
- Pages de point de contrôle/sec : Pages vidées par un point de contrôle ou d'autres opérations nécessitant le vidage de toutes les pages sales
3.4.2 Compteurs de statistiques SQL
Ces compteurs donnent un aperçu de SQL Server traitement des requêtes :
- Requêtes par lots/sec : Nombre de requêtes SQL par lots reçues par le serveur. Ce chiffre sert de référence pour l'activité du serveur.
- Compilations SQL/sec : Nombre de compilations SQL. Doit être inférieur ou égal à 10 % du nombre total de requêtes batch/s.
- Recompilations SQL/sec : Nombre de recompilations SQL. Doit également être inférieur ou égal à 10 % du nombre total de requêtes batch/s.
3.4.3 Compteurs de statistiques générales
- Connexions utilisateur : Nombre d'utilisateurs connectés au système. Utilisé comme référence pour suivre la croissance des connexions au fil du temps.
- Processus bloqués : Nombre actuel de processus bloqués. Idéalement, il devrait être de 0.
3.4.4 Compteurs du gestionnaire de mémoire
- Subventions de mémoire en attente : Nombre total de processus en attente d'allocation de mémoire pour l'espace de travail. Idéalement, cette valeur devrait être nulle.
4. Configuration du moniteur de performances pour SQL Server(Windows Vista / Server 2008 et versions ultérieures)
Tout d’abord, nous devons créer un conteneur pour gérer les compteurs plus facilement :
- Pour Windows Vista / Server 2008 et les versions ultérieures, vous pouvez créer des ensembles de collecteurs de données dans cette section.
- Pour Windows XP / Server 2003 et les versions antérieures, vous pouvez créer des journaux de compteurs dans la section suivante.
4.1 Que sont les ensembles de collecteurs de données ?
Les ensembles de collecteurs de données regroupent les compteurs de performance, les données de suivi des événements et les informations de configuration système en une seule unité de collecte. Ils offrent une plus grande flexibilité que de simples journaux de compteurs et permettent une collecte de données automatisée et planifiée pour une surveillance complète des performances des bases de données SQL.
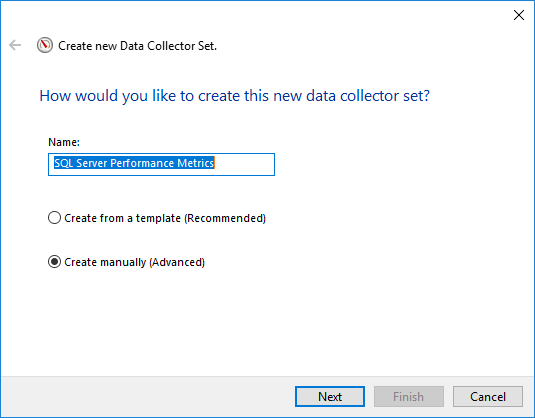
4.2 Création d'un ensemble de collecteurs de données
Créer un ensemble de collecteurs de données personnalisé à surveiller SQL Server compteurs de performance :
- Ouvrir le moniteur de performances
- Afficher Ensembles de collecteurs de données
- Faites un clic droit Défini par l'utilisateur
- Choisir NOUVEAU -> Ensemble de collecteurs de données

- Saisissez un nom descriptif (par exemple, «SQL Server « Mesures de performance »)
- Choisir Créer manuellement (avancé)

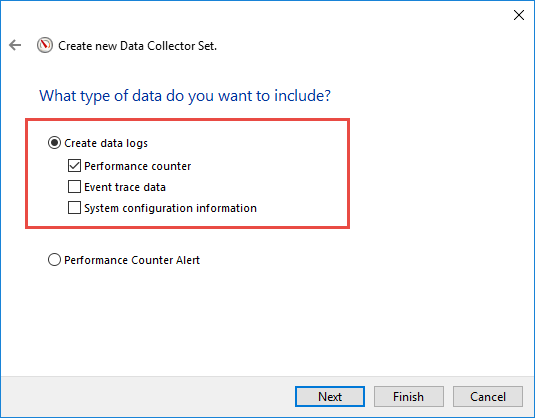
- Cliquez à nouveau sur Suivant
- Vérifiez Créer des journaux de données -> Compteur de performances
- Cliquez à nouveau sur Suivant
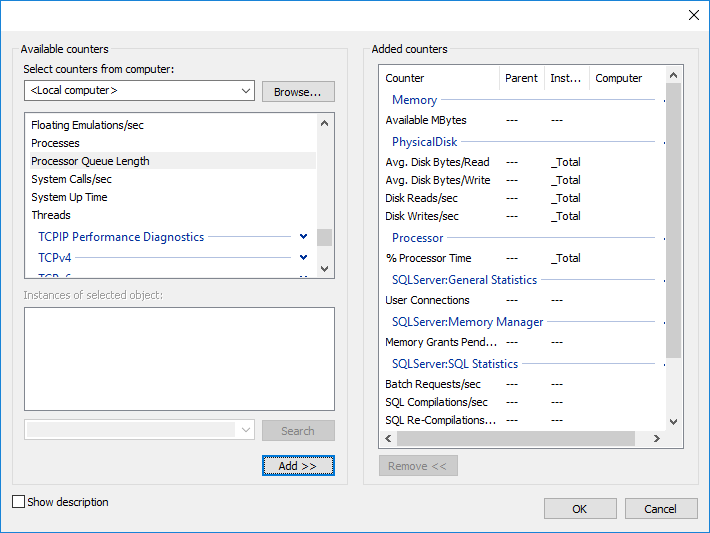
- Cliquez à nouveau sur Ajouter pour sélectionner les compteurs
- Ajouter voulu SQL Server et compteurs système.

- complet » Intervalle d'échantillonnage
- Pour une surveillance de routine, utilisez 1 minute (60 secondes)
- Pour un dépannage actif, utilisez 15 à 30 secondes
- Évitez d’exécuter des captures à haute fréquence à long terme, car elles peuvent avoir un impact sur les performances et générer des données excessives.
- Cliquez à nouveau sur Suivant
- Choisissez l'emplacement pour enregistrer les journaux
- Cliquez à nouveau sur Finition, un nouvel ensemble de collecteurs de données sera créé.
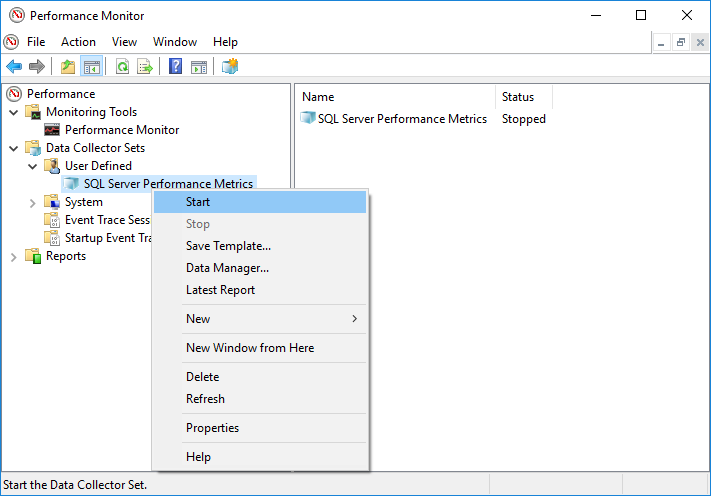
- Par défaut, le nouvel ensemble de collecteurs de données sera pas être starautomatiquement. Vous devez le trouver dans le panneau de gauche, sous Performances -> Ensembles de collecteurs de données -> Défini par l'utilisateur -> Votre collecteur de données, faites un clic droit dessus et choisissez Commencer

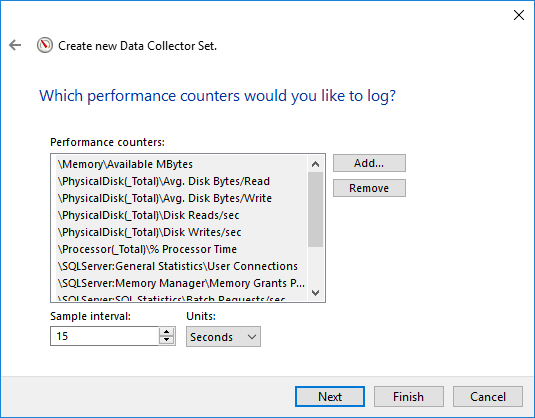
4.3 Compteurs clés à ajouter
- Mémoire -> Mo disponibles
- Disque physique -> Durée moyenne du disque en secondes/lecture (toutes les instances sauf _Total)
- Disque physique -> Moyenne disque sec/écriture (toutes les instances sauf _Total)
- Disque physique -> Lectures de disque/s (toutes les instances sauf _Total)
- Disque physique -> Écritures sur disque/s (toutes les instances sauf _Total)
- Processeur -> % Temps processeur (toutes les instances sauf _Total)
- SQLServer : Statistiques générales -> Connexions utilisateur
- SQLServer : Gestionnaire de mémoire -> Octrois de mémoire en attente
- SQLServer : Statistiques SQL -> Requêtes par lots/s
- SQLServer : Statistiques SQL -> Compilations SQL/s
- SQLServer : Statistiques SQL -> Recompilations SQL/s
- Système -> Longueur de la file d'attente du processeur
4.4 Définition des conditions d'arrêt
Configurer les conditions d’arrêt pour empêcher la croissance illimitée des données :
- Après avoir créé l'ensemble de collecteurs de données, cliquez dessus avec le bouton droit de la souris et sélectionnez Propriétés
- Cliquez sur Condition d'arrêt languette
- Permettre Durée totale
- Définir la durée sur 1 jour (24 heures)
- Cliquez à nouveau sur OK pour sauver
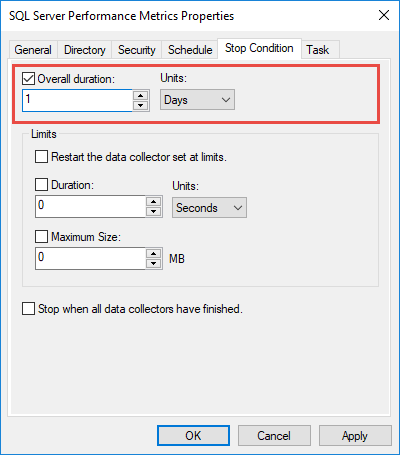
Cela garantit que le journal ne devient pas trop volumineux et se réinitialise automatiquement.tarts si prévu.
4.5 Planification de la collecte de données
Automatisez la collecte de données pour garantir une surveillance cohérente :
- Cliquez avec le bouton droit sur votre ensemble de collecteurs de données et sélectionnez Propriétés
- Cliquez sur Horaires languette
- Cliquez à nouveau sur Ajouter pour créer un nouveau planning
- Configurer stardate et heure
- Définir un modèle de récurrence (par exemple, quotidien)
- Cliquez à nouveau sur OK pour sauvegarder le planning
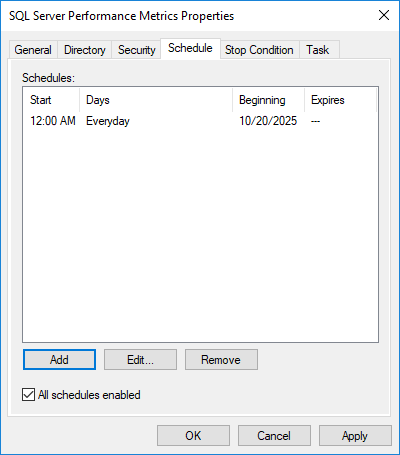
Pour les s automatiquestartup, configurez l'ensemble de collecteurs de données sur start lorsque le serveur démarre en créant commetardéclencheur tup dans le planificateur de tâches Windows.
5. Configuration du moniteur de performances pour SQL Server(Windows XP / Server 2003 et versions antérieures)
Pour Windows XP / Server 2003 et les versions antérieures, vous pouvez créer des journaux de compteurs, qui vous permettent de sélectionner un ensemble de compteurs de performances et de les enregistrer périodiquement dans un fichier.
5.1 Création de journaux de compteurs
Suivez ces étapes pour créer un nouveau journal de compteur :
- Ouvrir le moniteur de performances
- Afficher Journaux et alertes de performances dans le volet gauche
- Faites un clic droit Journaux de compteur
- Choisir Nouveaux paramètres de journal
- Nommez le journal avec le nom de votre serveur de base de données (par exemple, « ProductionSQL01 »)
- Cliquez à nouveau sur OK pour commencer la configuration
La création de journaux de compteurs distincts pour chaque serveur vous permet de tester les performances sur des serveurs individuels sans collecter de données pour tous les serveurs simultanément.
5.2 Ajout de compteurs de performances
Après avoir créé un journal de compteurs, ajoutez les compteurs de performances spécifiques que vous souhaitez surveiller :
- Cliquez sur Ajouter des compteurs bouton (dans la fenêtre de contrôle qui apparaît maintenant)
- Modifiez le nom de l'ordinateur pour qu'il pointe vers votre SQL Server instance
- Presse Languette pour charger les objets de performance disponibles
- Sélectionnez un objet de performance dans la liste déroulante (par exemple, Mémoire)
- Choisissez des compteurs spécifiques parmi la liste
- Sélectionnez les instances si elles s'appliquentcable (par exemple, processeurs ou disques individuels)
- Cliquez à nouveau sur Ajouter pour inclure le compteur
- Répétez l'opération pour tous les compteurs souhaités
- Cliquez à nouveau sur Fermer Une fois terminé
5.3 Configuration des intervalles d'échantillonnage
L'intervalle d'échantillonnage détermine la fréquence de collecte des données par l'Analyseur de performances. Configurez des intervalles adaptés à vos besoins de surveillance :
- Dans les propriétés du journal du compteur, recherchez Données d'échantillon toutes les
- Définissez l'intervalle (la valeur par défaut est 15 secondes)
- Pour la surveillance de base, utilisez des intervalles d'une minute pour la collecte quotidienne
- Pour le dépannage, utilisez des intervalles de 15 à 30 secondes pour de courtes rafales
- Cliquez à nouveau sur OK appliquer
N'oubliez pas que des intervalles plus courts génèrent davantage de données, ce qui peut être plus difficile à restituer et à analyser. Des intervalles plus longs peuvent manquer des pics importants. Trouvez le juste équilibre entre la granularité des données et les exigences de stockage et d'analyse.
5.4 Configuration des fichiers journaux
Une configuration appropriée du fichier journal garantit que les données sont stockées de manière efficace et accessible :
- Cliquez sur Fichiers log onglet dans les propriétés du journal du compteur
- Changer le type de fichier journal en Fichier texte (délimité par des virgules) pour une importation Excel facile
- Cliquez à nouveau sur Configurez
- Définissez le chemin d'accès au fichier vers un emplacement dédié (par exemple, un dossier PerformanceLogs partagé)
- Cliquez à nouveau sur OK confirmer
Utilisez un partage accessible au réseau pour le stockage des journaux afin de pouvoir accéder aux fichiers à distance et les partager avec d’autres utilisateurs.
5.5 Configuration des informations d'identification
Configurez les informations d'identification appropriées pour que Performance Monitor puisse accéder à distance SQL Server les instances:
- Dans les propriétés du journal du compteur, recherchez Courir comme
- Saisissez le nom d'utilisateur de votre domaine au format : DOMAINE\nom d'utilisateur
- Cliquez à nouveau sur Définir mot de passe
- Entrez et confirmez votre mot de passe
- Cliquez à nouveau sur OK pour sauver
Cela permet au service PerfMon de collecter des statistiques en utilisant les autorisations de votre domaine plutôt que ses propres informations d'identification.
6. Analyse des données du moniteur de performances
6.1 Affichage des fichiers journaux dans le moniteur de performances
Performance Monitor peut afficher les données historiques des fichiers journaux enregistrés :
- Ouvrir le moniteur de performances
- Dans le volet de gauche, cliquez sur Outils de surveillance -> Analyseur de performances.
- Cliquez avec le bouton droit n'importe où dans la zone graphique
- Choisir Propriétés

- Cliquez sur Matériau languette
- Choisir Log files bouton radio
- Cliquez à nouveau sur Ajouter
- Accédez à votre fichier journal (.blg ou .csv)
- Sélectionnez le fichier et cliquez sur Ouvrez

- Utilisez le bouton Intervalle de temps curseur pour sélectionner la période que vous souhaitez analyser
- Cliquez à nouveau sur OK pour fermer la boîte de dialogue Propriétés
- Cliquez sur l'icône verte plus pour ajouter des compteurs à partir du fichier journal
- Sélectionnez les compteurs souhaités à afficher
- Cliquez à nouveau sur OK
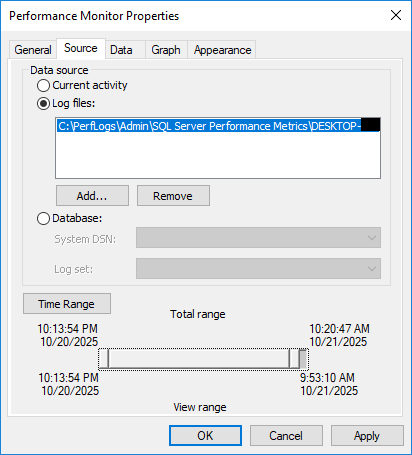
Le graphique affichera désormais les données historiques du fichier journal. Utilisez le curseur « Période » dans les Propriétés pour affiner les périodes et obtenir une analyse détaillée.
6.2 Exportation de données vers Excel
Excel fournit de puissantes capacités d’analyse pour les données des compteurs de performances :
- Ouvrez le Moniteur de performances avec votre fichier journal chargé
- Cliquez avec le bouton droit n'importe où dans la zone graphique
- Choisir Enregistrer les données sous
- Choisissez un emplacement pour le fichier
- Choisir Fichier texte (délimité par des virgules) (.csv) dans la liste déroulante
- Cliquez à nouveau sur Enregistrer
- Ouvrir le fichier CSV dans Excel
Formater les données exportées pour une meilleure analyse :
- Supprimez la ligne 2 à moitié vide et effacez la cellule A1
- Formater la colonne A comme Date/Heure
- Formater les colonnes numériques avec zéro décimale et séparateur de milliers
- Rechercher et remplacer les noms de serveur dans les en-têtes (par exemple, remplacer « \\SERVERNAME » par un espace vide)
- Nettoyer les noms d'objets dans les en-têtes (par exemple, « Mémoire », « Disque physique », « Processeur »)
- Réduisez la taille de la police de l'en-tête à 8 points pour une meilleure visibilité
6.3 Interprétation des valeurs de compteur
6.3.1 Analyse du compteur de mémoire
Lors de l'analyse des compteurs de mémoire, recherchez ces indicateurs :
- Mo disponibles : Doit rester constamment au-dessus de 4 096 Mo
- Durée de vie de la page : Des valeurs supérieures à 300 secondes indiquent une mémoire saine. Des valeurs inférieures suggèrent une pression sur la mémoire.
- Taux de réussite du cache tampon : Doit atteindre ou dépasser 99 %. Des valeurs inférieures indiquent un nombre excessif de lectures sur disque.
- Subventions de mémoire en attente : Doit toujours être 0. Toute valeur positive indique la mémoire starvation
6.3.2 Analyse du compteur CPU
Les indicateurs de performance du processeur incluent :
- % Temps processeur : Une utilisation prolongée supérieure à 75 % indique des problèmes de performances. Des pics à 100 % sont normaux, mais ne devraient pas persister.
- Longueur de la file d'attente du processeur : Les valeurs supérieures à 1 indiquent une sollicitation du processeur. Consultez le Gestionnaire des tâches pour identifier les processus qui sollicitent le processeur.
- % Temps privilégié : Devrait rester entre 5 et 10 %. Des valeurs supérieures à 25 % suggèrent des opérations d'E/S excessives.
6.3.3 Analyse du compteur de disque
Seuils de performances du disque :
- Moy. Disque sec/Lecture et écriture : Doit rester inférieur à 10-20 ms. Des valeurs supérieures indiquent des sous-systèmes de disque lents.
- Longueur de la file d'attente du disque : Des valeurs systématiquement supérieures à 2 (ou 2 par disque en RAID) indiquent des goulots d'étranglement d'E/S
- % Temps disque : Des valeurs soutenues supérieures à 85 % indiquent une saturation du disque
6.4 Utilisation de formules et de statistiques
Ajoutez des formules statistiques à Excel pour une analyse rapide :
- Insérez 7 lignes vides en haut de votre feuille de calcul
- Ajoutez des étiquettes dans la colonne A : Moyenne, Médiane, Min, Max, Écart type
- Dans la cellule B2, saisissez : =MOYENNE(B9:B100) (ajustez B100 à votre dernière ligne de données)
- Dans la cellule B3, saisissez : =MEDIAN(B9:B100)
- Dans la cellule B4, saisissez : =MIN(B9:B100)
- Dans la cellule B5, saisissez : =MAX(B9:B100)
- Dans la cellule B6, saisissez : =STDEV(B9:B100)
- Copier les formules dans toutes les colonnes du compteur
- Sélectionnez la cellule B9 et appuyez sur Alt+W+F+Entrée pour figer les volets
Ces statistiques aident à identifier les tendances, les valeurs aberrantes et les plages de fonctionnement normales pour chaque compteur.
7. Outil d'analyse des performances des journaux (PAL)
7.1 Introduction au PAL
Performance Analysis for Logs (PAL) est un outil gratuit développé par Clint Huffman qui analyse les journaux du Moniteur de Performances et génère des rapports HTML avec analyse des seuils. PAL compare vos données de performance à des seuils connus et fournit des recommandations détaillées. SQL Server optimisation des performances.
Téléchargez PAL depuis le dépôt GitHub : https://github.com/clinthuffman/PAL ![]()
7.2 Configuration PAL
Installez PAL en suivant ces étapes :
- Téléchargez le fichier d'installation PAL depuis GitHub
- Exécutez le programme d'installation
- Cliquez à nouveau sur Suivant sur l'écran d'accueil
- Vérifiez et acceptez le répertoire d'installation
- Cliquez à nouveau sur Suivant à continuer
- Cliquez à nouveau sur Installer pour commencer l'installation
- Attendez que l'installation soit terminée
- Cliquez à nouveau sur Finition
7.3 Traitement des fichiers journaux avec PAL
Analysez vos journaux Performance Monitor à l'aide de PAL :
- Lancement PAL depuis le Starmenu t ou répertoire d'installation
- Cliquez sur Journal du compteur languette
- Cliquez à nouveau sur Explorer pour sélectionner votre fichier .blg
- Accédez à votre fichier journal du moniteur de performances
- Cliquez à nouveau sur Ouvrez
- Cliquez sur Fichier de seuil languette
- Sélectionnez un fichier de seuil dans la liste déroulante (par exemple, «SQL Server 2016 ”)
- Cliquez sur Questions que languette
- Répondez aux questions sur la configuration de votre système
- Précisez si votre SQL Server est-ce OLTP ou Data Warehouse
- Entrez la RAM totale disponible
- Cliquez sur Options de sortie languette
- Sélectionnez un répertoire de sortie pour le rapport HTML
- Vérifiez HTML format de sortie
- Cliquez sur Exécution languette
- Revoyez vos sélections
- Vérifiez Start exécution maintenant
- Cliquez à nouveau sur Finition
7.4 Analyse des rapports PAL
Une fois l'analyse terminée, PAL génère un rapport HTML contenant :
- Résumé des problèmes de performance
- Analyse détaillée des compteurs avec graphiques
- Les violations de seuil sont mises en évidence en couleur
- Recommandations spécifiques pour chaque problématique
- Tendances et modèles historiques
Le rapport utilise un code couleur pour indiquer la gravité : rouge pour les problèmes critiques, jaune pour les avertissements et vert pour les indicateurs sains. Consultez chaque section pour comprendre les goulots d'étranglement des performances et suivre les recommandations d'optimisation de PAL.
8ème alternative SQL Server Outils de surveillance
8.1 Intégré SQL Server Outils
8.1.1 SQL Server Moniteur d'activité
SQL Server Moniteur d'activité affiche des informations en temps réel sur SQL Server processus et performances :
- Ouvrez SQL Server Management Studio (SSMS) et connectez-vous à votre instance de serveur
- Cliquez avec le bouton droit sur le nom du serveur dans l'Explorateur d'objets
- Choisir Moniteur d'activité

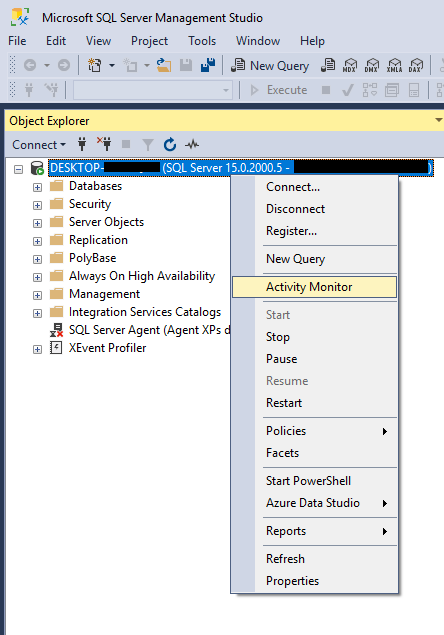
Le moniteur d'activité affiche les processus, les attentes de ressources, les entrées/sorties des fichiers de données et les requêtes coûteuses récentes. Il fournit un aperçu rapide de l'activité actuelle de la base de données, mais ne conserve pas d'historique.
8.1.2 SQL Server Tableau de bord des performances
SQL Server Management Studio inclut des rapports de performances intégrés :
- In SQL Server Management Studio (SSMS), cliquez avec le bouton droit sur SQL Server instance dans l'explorateur d'objets
- Choisir Rapports -> Rapports standard
- Choisissez parmi les rapports disponibles tels que Tableau de bord des performances

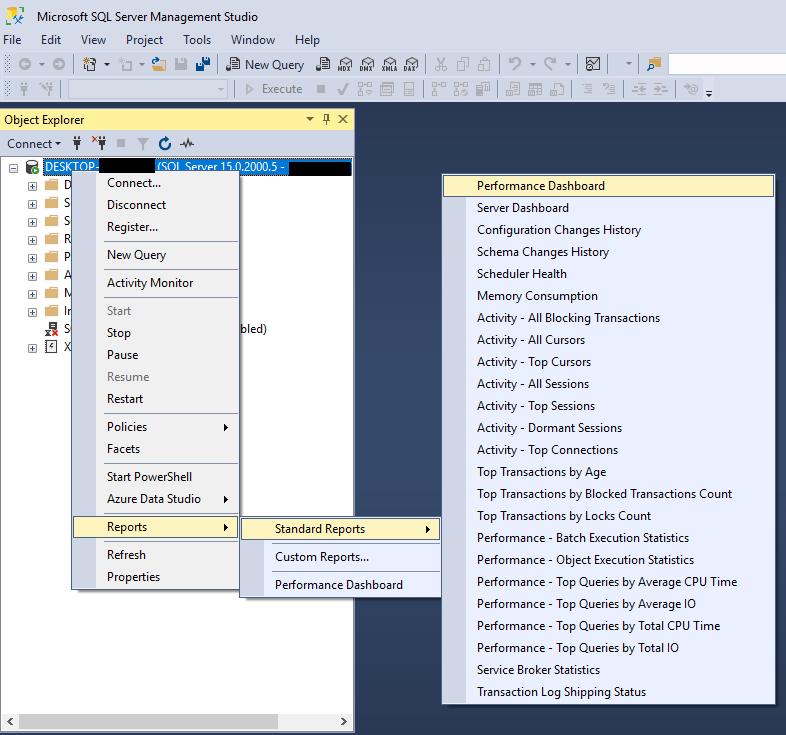
Le tableau de bord des performances fournit des informations visuelles sur SQL Server Performances de l'instance, incluant l'utilisation du processeur système, les requêtes en attente et les indicateurs de performance. Accédez à ces informations via le menu « Rapports standard ».
8.1.3 SQL Server Profiler
SQL Server Profiler capture et analyse SQL Server des événements tels que l’exécution de requêtes, les opérations de transaction et les activités de connexion.
À start SQL Server Profileur :
- In SQL Server Management Studio, cliquez Outils -> SQL Server Profiler

Le profileur engendre une surcharge de performances significative ; utilisez-le donc judicieusement et de préférence en heures creuses.ost scénarios, les événements étendus offrent de meilleures performances avec moins d'impact.
8.1.4 Événements étendus
Événements étendus est un système de surveillance des performances léger intégré dans SQL Server. Il remplace SQL Server Profileur avec de meilleures performances et une surcharge réduite.
Les principales caractéristiques comprennent:
- Surveillance fine d'événements spécifiques
- Impact minimal sur les performances
- Sessions d'événements personnalisables
- Intégration avec SSMS et d'autres outils
- Prise en charge du filtrage et de l'agrégation complexes
Créer des sessions d'événements étendus via SSMS :
- In Explorateur d'objets, développez votre serveur et accédez à Gestion -> Événements étendus -> Sessions
- Faites un clic droit sur le Sessions et choisissez Assistant de nouvelle session

- Suivez les instructions pour starune nouvelle session.
8.1.5 Vues de gestion dynamique (DMV)
Les DMV fournissent des informations détaillées sur l'état du serveur pour surveiller son état, diagnostiquer les problèmes et optimiser les performances. Parmi les principaux DMV, on trouve :
- sys.dm_exec_query_stats : Statistiques de performances des requêtes
- sys.dm_os_wait_stats : Types d'attente affectant les performances du serveur
- compteurs_performance_os_sys.dm : SQL Server données du compteur de performance
- sys.dm_exec_requests : Exécution des requêtes en cours
- sessions sys.dm_exec : Sessions utilisateur actives
Interrogez ces vues à l’aide de T-SQL pour accéder aux données de performances en temps réel et aux mesures historiques.
Utilisation de base
-- See all active connections
SELECT * FROM sys.dm_exec_connections;
-- View current sessions
SELECT * FROM sys.dm_exec_sessions;
-- Check database file stats
SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL);8.2 Solutions de surveillance tierces
Moniteur SQL Redgate
Redgate SQL Monitor est spécialisé dans la surveillance SQL Server et les environnements de base de données Azure SQL. Il offre une surveillance à l'échelle du domaine, des alertes et des tableaux de bord personnalisables, des fonctionnalités de reporting détaillées et une intégration avec d'autres outils Redgate.
SolarWinds SQL Server Outil de surveillance
Les vents solaires SQL Server L'outil de surveillance, également connu sous le nom de SQL Sentry, est conçu pour diagnostiquer, résoudre et prévenir de graves problèmes de performances avec SQL Server.
IDERA SQL Server Outil de surveillance des performances
Diagnostic IDERA SQLostic Manager est un puissant SQL Server outil de surveillance des performances conçu pour faciliter la surveillance proactive des performances, le diagnosticostics et réglage.
Surveillance SQL du gestionnaire d'applications
Applications Manager propose un Microsoft SQL Server Outil de surveillance qui fournit des solutions informatiques utiles. Il est conçu pour superviser les performances des bases de données SQL, tout en identifiant simultanément les bogues et en résolvant les problèmes susceptibles d’entraîner l’arrêt des opérations d’une organisation.
8.3 Outils de surveillance open source
Tableau de bord DBA
DBA Dash est un outil de surveillance gratuit et open source qui fournit des informations sur SQL Server Santé, performances et activité. Particulièrement utile pour les environnements de petite et moyenne taille, il inclut des vérifications quotidiennes des administrateurs de bases de données, la surveillance des performances et le suivi de la configuration.
SQLWATCH
SQLWATCH propose des solutions décentralisées, en temps quasi réel SQL Server Surveillance avec une précision de 5 secondes pour détecter les pics de charge de travail. Il prend en charge Grafana pour les tableaux de bord en temps réel et Power BI pour une analyse approfondie. L'outil offre de nombreuses options de configuration, une maintenance nulle et une évolutivité illimitée.
Opserver
Développé par Stack Exchange, Opserver surveille plusieurs systèmes, notamment SQL Server, Redis et Elasticsearch. Il offre une vue « tous les serveurs » pour les statistiques CPU, mémoire, réseau et matériel de votre infrastructure.
sp_WhoIsActive
sp_WhoIsActive est une procédure stockée complète de surveillance d'activité créée par Adam Machanic. Elle fonctionne avec tous les SQL Server versions de 2005 aux versions actuelles et est largement utilisé par SQL Server DBA pour la surveillance des activités en temps réel.
Pour utiliser sp_WhoIsActive, téléchargez-le depuis http://whoisactive.com/, installez-le dans votre base de données et exécutez :
EXEC sp_WhoIsActive
La procédure affiche les requêtes en cours d'exécution, les informations d'attente, les détails de blocage et la consommation des ressources.
9. Meilleures pratiques pour SQL Server Analyseur de performances
9.1 Établissement de références de performance
Les lignes de base de performance établissent les paramètres de fonctionnement normaux pour votre SQL Server Environnement. Sans références, il est impossible de déterminer si les indicateurs actuels indiquent des problèmes ou représentent un comportement typique.
Créer des lignes de base en :
- Collecte de données de performance pendant les opérations normales pendant au moins une semaine
- Capture des métriques pendant les heures de pointe et les heures creuses
- Documentation des valeurs typiques pour les compteurs clés
- Enregistrement des variations saisonnières si applicablecable
- Stockage des données de base pour comparaison avec les mesures futures
Mettre à jour les lignes de base trimestriellement ou après des changements d'infrastructure importants, des mises à jour d'applications ou des modifications de base de données.
9.2 Définition de seuils d'alerte appropriés
Configurez des seuils intelligents pour recevoir des alertes significatives sans vous submerger de notifications :
- Les allocations de mémoire en attente > 0 indiquent une pression sur la mémoire
- Une longueur de file d'attente du processeur > 2 par cœur suggère un goulot d'étranglement du processeur
- Disque sec/Lecture ou écriture > 20 ms indique des E/S lentes
- Processus bloqués > 5 signalent des problèmes de contention
- Une espérance de vie de page < 300 secondes indique une pression sur la mémoire
Ajustez les seuils en fonction de vos données de référence et des caractéristiques spécifiques de votre charge de travail. Utilisez des seuils adaptatifs qui tiennent compte des variations normales de votre environnement.
9.3 Examen et analyse réguliers des données
Planifiez des évaluations de performance régulières pour identifier les tendances et les problèmes émergents :
- Quotidien : Consultez les indicateurs de haut niveau et les alertes récentes
- Hebdomadaire : Effectuer une analyse approfondie des tendances de performance
- Mensuel : générer des rapports complets et les comparer aux données de référence
- Trimestriel : Examiner la planification des capacités et les tendances à long terme
Documentez les résultats et suivez les améliorations des performances au fil du temps.
9.4 Équilibrage des frais généraux de surveillance
La surveillance elle-même consomme des ressources, il faut donc équilibrer la collecte de données avec l'impact sur les performances :
- Utilisez des intervalles de 30 à 60 secondes pour une surveillance continue
- Utilisez des intervalles de 15 secondes uniquement pour le dépannage actif
- Limiter la collecte de données Définir la durée pour éviter les données excessives
- Stocker les journaux sur des lecteurs distincts des fichiers de base de données
- Archiver les anciennes données de performances pour maintenir des tailles de fichiers gérables
Performance Monitor ajoute une surcharge minimale lorsqu'il est configuré correctement, généralement moins de 2 % des ressources système.
9.5 Conservation des données à long terme
Conservez les données de performance pour une analyse des tendances significative et une planification des capacités :
- Conservez au moins 1 à 2 ans de données de performance
- Archiver les données dans un stockage séparé après 3 à 6 mois
- Compressez les anciens fichiers journaux pour économiser de l'espace
- Documentez tous les événements ou changements importants qui affectent les performances
Étant donné la taille relativement petite des données des compteurs de performances, leur conservation indéfinie est souvent réalisable et utile pour une analyse à long terme.
9.6 Intégration aux pratiques DevOps
Intégrer la surveillance des performances de la base de données dans les pipelines CI/CD :
- Inclure les mesures de performance de la base de données dans la validation du déploiement
- Automatiser les tests de performances pour les nouvelles versions
- Valider que les modifications du code n'ont pas d'impact négatif sur les performances
- Créer des benchmarks de performances pour chaque version
- Intégrer les alertes de surveillance aux systèmes de gestion des incidents
10. Dépannage des problèmes de performances courants
10.1 Identification des goulots d'étranglement du processeur
Les goulots d'étranglement du processeur se manifestent par des temps de réponse lents aux requêtes et une utilisation intensive du processeur. Suivez ces étapes pour diagnostiquer les problèmes de processeur :
- Vérifiez le compteur de longueur de file d'attente du processeur. Une valeur supérieure à 2 par cœur indique une sollicitation du processeur.
- Vérifiez le % de temps processeur. Des valeurs soutenues supérieures à 75 % suggèrent un goulot d'étranglement du processeur.
- Bureau à distance vers le SQL Server
- Ouvrir le Gestionnaire des tâches (Ctrl+Maj+Échap)
- Cliquez sur Processus languette
- Vérifiez Afficher les processus de tous les utilisateurs
- Cliquez sur Processeur en-tête de colonne pour trier par utilisation du processeur
- Identifier les processus qui consomment des ressources CPU
Si non-SQL Server Les applications consomment beaucoup de CPU ; supprimez-les du serveur de base de données. Si sqlservr.exe consomme beaucoup de CPU, examinez-les en utilisant les méthodes suivantes :
- Vérifiez les compilations et recompilations SQL/s. Des valeurs supérieures à 10 % de requêtes par lot/s indiquent une compilation excessive.
- Interrogez sys.dm_exec_query_stats pour identifier les requêtes gourmandes en ressources CPU
- Examiner les plans d'exécution pour détecter les index manquants ou les opérations inefficaces
- Envisagez d'ajouter des index pour réduire les analyses de table
10.2 Diagnostic des problèmes de mémoire
Les problèmes de mémoire ont un impact significatif SQL Server Performances. Diagnostiquez les problèmes de mémoire à l'aide de ces indicateurs :
Gouttes de mémoire disponibles
Si les Mo disponibles tombent régulièrement en dessous de 100 Mo, le système d'exploitation est confronté à des problèmes de mémoire.tarvation. Windows peut paginer SQL Server mémoire sur disque, provoquant une dégradation des performances.
Faible espérance de vie des pages
Une durée de vie de page inférieure à 300 secondes indique une rotation élevée du cache tampon. Cela suggère soit une allocation mémoire insuffisante, soit une sollicitation mémoire excessive due aux requêtes.
Faible taux de réussite du cache tampon
Un taux de réussite du cache tampon inférieur à 99 % signifie SQL Server lit fréquemment les données depuis le disque plutôt que depuis la mémoire. Cela se produit lorsque le pool de mémoire tampon est trop petit ou SQL Server se réchauffe encore après la réanimationtart.
Subventions de mémoire en attente
Toute valeur supérieure à 0 pour « Allocations de mémoire en attente » indique que des requêtes sont en attente d'allocations de mémoire. Cela indique un manque critique de mémoire nécessitant une intervention immédiate.
Pour résoudre les problèmes de mémoire :
- Configurez SQL Server paramètre de mémoire maximale pour laisser suffisamment de RAM pour le système d'exploitation (généralement 4 à 8 Go selon la taille du serveur)
- Activer l'autorisation « Verrouiller les pages en mémoire » pour le SQL Server compte de service
- Ajoutez plus de RAM physique au serveur si la pression de la mémoire persiste
- Identifier et optimiser les requêtes gourmandes en mémoire
10.3 Résolution des problèmes d'E/S de disque
Les E/S disque constituent souvent le principal goulot d'étranglement des performances des systèmes de bases de données. Diagnostiquez les problèmes de disque grâce aux méthodes suivantes :
Longueur de file d'attente de disque élevée
Une longueur de file d'attente de disque constamment supérieure à 2 (ou 2 par disque pour RAID) indique que le sous-système de disque ne peut pas gérer les requêtes d'E/S. Cela crée un retard d'opérations en attente.
Latence excessive du disque
Des valeurs de temps de lecture moyen et d'écriture moyen supérieures à 10-20 ms indiquent une réponse lente du disque. Les lecteurs de journaux de transactions nécessitent des performances particulièrement élevées, idéalement inférieures à 5 ms en écriture.
% de temps disque élevé
Un pourcentage de temps disque soutenu supérieur à 85 % indique une saturation du disque. Le disque passe most de son temps de traitement des requêtes d'E/S avec peu de capacité inactive restante.
Avant de résoudre les problèmes de disque, vérifiez qu'ils ne sont pas le symptôme d'un problème de mémoire. Une mémoire insuffisante force SQL Server pour lire plus de données à partir du disque, en gonflant artificiellement les métriques du disque.
Pour résoudre les problèmes d’E/S de disque authentiques :
- Passez à des disques plus rapides (SSD au lieu de HDD)
- Implémenter des configurations RAID pour de meilleures performances
- Séparez les fichiers de base de données, les journaux de transactions et tempdb sur différents disques physiques
- Ajoutez plus de mémoire pour réduire les lectures sur disque
- Optimiser les index pour réduire les E/S inutiles
- Examiner et optimiser les requêtes peu performantes
10.4 Traitement des blocages et des impasses
Un blocage se produit lorsqu'une session est verrouillée, empêchant ainsi les autres sessions de se poursuivre. Surveillez les compteurs suivants pour identifier les blocages :
- Processus bloqués : Devrait idéalement être 0
- Attentes de verrouillage/sec : Nombre de demandes de verrouillage nécessitant une attente
- Temps d'attente moyen : Durée moyenne des attentes de verrouillage
Pour enquêter sur le blocage :
- Ouvrir le moniteur d'activité dans SSMS
- Élargir la Processus
- Rechercher des processus avec une valeur non nulle Bloqué par valeurs
- Identifier l'ID de session de blocage
- Examiner les requêtes provoquant le blocage
Utilisez sp_WhoIsActive pour une analyse de blocage plus détaillée. Un nombre excessif d'entrées wait_info indique souvent des conflits ou des problèmes de blocage dans tempdb.
Pour réduire le blocage :
- Réduire la durée des transactions
- Utiliser des niveaux d'isolement appropriés
- Ajouter des index pour réduire la durée du verrouillage
- Considérez l'isolation de READ_COMMITTED_SNAPSHOT
- Examiner et optimiser les requêtes de longue durée
10.5 Problèmes de performances des requêtes
L'identification des requêtes coûteuses est essentielle pour la surveillance des performances SQL. Utilisez les méthodes suivantes pour identifier les requêtes problématiques :
Utilisation du moniteur d'activité
- Dans SSMS, faites un clic droit sur le nom du serveur
- Choisir Moniteur d'activité
- Afficher Requêtes coûteuses récentes
- Examiner les requêtes nécessitant une utilisation élevée du processeur, une durée élevée ou des lectures logiques
Utilisation des DMV
Interrogez sys.dm_exec_query_stats pour identifier les requêtes gourmandes en ressources :
SELECT TOP 50
total_worker_time/execution_count AS avg_cpu_time,
total_logical_reads/execution_count AS avg_logical_reads,
execution_count,
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS query_text
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY total_worker_time DESC
Analyse des plans d'exécution
- Dans SSMS, ouvrez une nouvelle fenêtre de requête
- Cliquez à nouveau sur Afficher le plan d'exécution estimé (Ctrl+L) ou Inclure le plan d'exécution réel (Ctrl+M)
- Exécutez votre requête
- Revoir le plan d'exécution des opérations coûteuses
- Recherchez des analyses de table, des analyses d'index ou des analyses à haute résolutionost
Optimiser les requêtes en :
- Ajout d'index appropriés
- Réécrire les requêtes pour éviter des opérations coûteuses
- Mise à jour des statistiques
- Utiliser des noms de colonnes spécifiques au lieu de SELECT *
- Éviter les clauses DISTINCT ou ORDER BY inutiles
10.6 Détecter et réparer une base de données corrompue
La corruption d'une base de données peut entraîner une dégradation des performances, des pertes de données et des pannes système. Détecter et corriger rapidement toute corruption est essentiel pour préserver l'intégrité de la base de données.
Indicateurs de corruption de base de données
Soyez attentifs à ces signes de corruption potentielle :
- Messages d'erreur dans SQL Server journal des erreurs (erreur 823, 824 ou 825)
- Erreurs d'application inattendues lors de l'accès à des tables spécifiques
- Performances de requête lentes sur des requêtes auparavant rapides
- SQL Server plantages ou résolutions inattenduestarts
- Pages suspectes apparaissant dans la table msdb.dbo.suspect_pages
Utilisation de DBCC CHECKDB pour la détection
DBCC CHECKDB est l'outil principal de détection de corruption de base de données. Exécutez-le régulièrement pour détecter les problèmes au plus tôt.
Surveillance des pages suspectes
SQL Server enregistre automatiquement les pages suspectes dans la base de données msdb :
SELECT
database_id,
file_id,
page_id,
event_type,
error_count,
last_update_date
FROM msdb.dbo.suspect_pages
WHERE event_type IN (1,2,3)
Toutes les lignes renvoyées indiquent des problèmes de corruption nécessitant une attention immédiate.
Stratégies de prévention de la corruption
- Activer la vérification de page avec l'option CHECKSUM
- Maintenir des sauvegardes régulières de la base de données
- Utiliser du matériel fiable avec correction d'erreurs
- Surveiller l'état du disque à l'aide des outils du fabricant
- Planifier des exécutions régulières de DBCC CHECKDB
- Rester SQL Server mis à jour avec les derniers correctifs
Options de récupération et de réparation
Si des corruptions sont détectées, vous pouvez essayer l'outil intégré DBCC CHECKDB pour les corriger. En cas d'échec, utilisez des outils tiers tels que DataNumen SQL Recovery qui peut faire face à de graves corruptions.
11. Techniques de surveillance avancées
11.1 Surveillance du magasin de requêtes
Query Store, introduit dans SQL Server 2016, capture automatiquement les données de performance des requêtes. Il fournit des informations précieuses sur le comportement des requêtes, les plans d'exécution et les tendances de performance.
Activation du magasin de requêtes
- Dans l'explorateur d'objets SSMS, cliquez avec le bouton droit sur une base de données
- Choisir Propriétés
- Cliquez sur Magasin de requêtes page
- In Mode de fonctionnement (demandé), sélectionnez Read Write
- Configurer des paramètres supplémentaires selon les besoins
- Cliquez à nouveau sur OK
Surveillance des performances des requêtes
Accéder aux rapports Query Store via l'Explorateur d'objets :
- Développer la base de données dans l'Explorateur d'objets
- Afficher Magasin de requêtes
- Sélectionnez parmi les rapports disponibles :
- Requêtes régressées
- Consommation globale des ressources
- Requêtes consommatrices de ressources les plus importantes
- Requêtes avec plans forcés
- Requêtes suivies
Détection de régression de plan
Query Store détecte automatiquement les modifications des plans d'exécution des requêtes et les baisses de performances. Consultez le rapport Requêtes régressées pour identifier les requêtes affectées par les modifications de plan.
Gestion des plans forcés
Lorsque Query Store identifie un meilleur plan d'exécution, forcez SQL Server pour l'utiliser :
- Ouvrir la requête dans Query Store
- Faites un clic droit sur le plan souhaité
- Choisir Plan de force
Cela améliore immédiatement les performances sans nécessiter de modifications de code.
11.2 Surveillance de la maintenance de l'index
La fragmentation des index dégrade les performances des requêtes au fil du temps. Surveillez et maintenez régulièrement les index pour garantir des performances optimales.
Vérification de la fragmentation
Utilisez cette requête pour vérifier la fragmentation de l’index :
SELECT
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
ps.avg_fragmentation_in_percent,
ps.page_count
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE ps.avg_fragmentation_in_percent > 10
AND ps.page_count > 1000
ORDER BY ps.avg_fragmentation_in_percent DESC
Exécutez cette requête en dehors des heures de pointe, car elle peut nécessiter beaucoup de ressources.
Analyse de la densité des pages
La densité des pages indique le niveau de remplissage des pages d'index. Une faible densité gaspille de l'espace et réduit les performances.
SELECT
OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
ps.avg_page_space_used_in_percent
FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, 'SAMPLED') ps
INNER JOIN sys.indexes i ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE ps.avg_page_space_used_in_percent < 75
Décisions de réorganisation ou de reconstruction
Choisissez les opérations de maintenance d’index en fonction des niveaux de fragmentation :
- Fragmentation 10-30 % : utiliser ALTER INDEX REORGANIZE
- Fragmentation > 30 % : utiliser ALTER INDEX REBUILD
- Fragmentation < 10 % : aucune action nécessaire
Les opérations de réorganisation nécessitent moins de ressources et peuvent être exécutées en ligne. Les opérations de reconstruction sont plus approfondies, mais consomment des ressources importantes.
11.3 Mises à jour des statistiques de la base de données
Aide aux statistiques de la base de données SQL ServerL'optimiseur de requêtes crée des plans d'exécution efficaces. Des statistiques obsolètes nuisent aux performances des requêtes.
Reconstruction automatique des statistiques
Activer les mises à jour automatiques des statistiques :
ALTER DATABASE DatabaseName SET AUTO_UPDATE_STATISTICS ON ALTER DATABASE DatabaseName SET AUTO_CREATE_STATISTICS ON
Statistiques de surveillance de la santé
Vérifiez quand les statistiques ont été mises à jour pour la dernière fois :
SELECT
OBJECT_NAME(s.object_id) AS TableName,
s.name AS StatisticsName,
STATS_DATE(s.object_id, s.stats_id) AS LastUpdated,
sp.rows,
sp.modification_counter
FROM sys.stats s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) sp
WHERE STATS_DATE(s.object_id, s.stats_id) < DATEADD(DAY, -7, GETDATE())
ORDER BY LastUpdated
Mettre à jour les statistiques manuellement si nécessaire :
UPDATE STATISTICS TableName WITH FULLSCAN
11.4 Collecte de données de performances personnalisées
Créez des solutions de surveillance des performances personnalisées en interrogeant directement sys.dm_os_performance_counters et en stockant les résultats dans des tables.
Création de scripts de collection personnalisés
Créez une procédure stockée pour collecter les données des compteurs de performances :
CREATE PROCEDURE dbo.CollectPerformanceCounters
AS
BEGIN
INSERT INTO dbo.PerformanceHistory (
SampleTime,
CounterName,
CounterValue
)
SELECT
GETDATE(),
counter_name,
cntr_value
FROM sys.dm_os_performance_counters
WHERE counter_name IN (
'Page life expectancy',
'Batch Requests/sec',
'Buffer cache hit ratio'
)
END
Utilisation de sys.dm_os_performance_counters
Interroger directement les compteurs de performances :
SELECT
object_name,
counter_name,
instance_name,
cntr_value,
cntr_type
FROM sys.dm_os_performance_counters
WHERE object_name LIKE '%Buffer Manager%'
ORDER BY counter_name
Stockage des données historiques
Créez un tableau pour stocker les mesures de performances au fil du temps :
CREATE TABLE dbo.PerformanceHistory (
ID INT IDENTITY PRIMARY KEY,
SampleTime DATETIME2 NOT NULL,
PageLifeExpectancy BIGINT,
BatchRequestsPerSec DECIMAL(18,4),
BufferCacheHitRatio DECIMAL(5,2)
)
CREATE CLUSTERED COLUMNSTORE INDEX CCI_PerformanceHistory
ON dbo.PerformanceHistory
Méthodes de stockage de données pivotées
Stockez les données au format pivot avec une ligne par heure d'échantillonnage et une colonne par compteur. Cela réduit l'espace de stockage et améliore les performances des requêtes par rapport au stockage d'une ligne par compteur et par échantillon.
11.5 Surveillance multi-serveurs
Pour les environnements avec plusieurs SQL Server cas, mettre en œuvre une surveillance centralisée.
Approche de surveillance centralisée
- Créer une base de données de surveillance dédiée sur un serveur distinct
- Collecter les données de tous les serveurs dans le référentiel central
- Utilisez le SQL Server Tâches d'agent pour exécuter des scripts de collecte
- Mettre en œuvre une collecte de compteurs de performances accessible au réseau
Surveillance du serveur distant
Configurez l'Analyseur de performances pour collecter des données depuis des serveurs distants en spécifiant les noms de serveur lors de l'ajout de compteurs. Assurez-vous que les règles de pare-feu autorisent le trafic de l'Analyseur de performances.
Rapports inter-serveurs
Créez des rapports qui comparent les performances sur plusieurs serveurs pour identifier les valeurs aberrantes et les déséquilibres de capacité.
12. surveillance SQL Server dans les environnements Cloud
12.1 Surveillance de la base de données Azure SQL
Azure SQL Database fournit des fonctionnalités de surveillance intégrées qui diffèrent de celles sur site SQL Server.
Intégration d'Azure Monitor
Azure Monitor collecte automatiquement les métriques de la base de données Azure SQL, notamment :
- Utilisation DTU ou vCore
- L'utilisation de mémoire
- Statistiques de connexion
- Blocages et délais d'attente
Accédez à ces métriques via le portail Azure ou l’API Azure Monitor.
Fonctionnalités de surveillance intégrées
La base de données Azure SQL comprend :
- Recommandations de réglage automatique
- Aperçu des performances des requêtes
- Informations intelligentes pour la détection des anomalies
- Alerte et diagnostic intégrésostics
Aperçu des performances des requêtes
Cette fonctionnalité permet de visualiser les requêtes les plus consommatrices de ressources, d'analyser leur durée et d'analyser l'historique des performances. Accédez-y via le portail Azure, sous votre ressource de base de données SQL.
12.2 Outils de surveillance cloud natifs
Les plateformes cloud proposent des solutions de surveillance natives optimisées pour leurs environnements :
- Azure Monitor et Application Insights pour Azure SQL Database
- AWS CloudWatch pour RDS SQL Server
- Surveillance Google Cloud pour le Cloud SQL Server
Ces outils s’intègrent parfaitement à l’infrastructure cloud et fournissent une surveillance unifiée de toutes les ressources cloud.
Surveillance de l'environnement hybride
Pour les déploiements hybrides couvrant les environnements locaux et cloud, utilisez des outils prenant en charge les deux environnements, tels que Redgate SQL Monitor, SolarWinds DPA ou des solutions personnalisées utilisant la collecte de données centralisée.
12.3 Différences de performances dans le Cloud
Cloud SQL Server les environnements ont des caractéristiques uniques :
Modèles d'allocation de ressources
Les fournisseurs de cloud utilisent différentes méthodes d'allocation des ressources (DTU, vCores, sans serveur) qui influencent l'interprétation des indicateurs de performance. Comprenez les limites et les caractéristiques de votre niveau de service.
Considérations relatives à la mise à l'échelle
Les environnements cloud offrent des capacités de scalabilité dynamique. Surveillez l'utilisation des ressources pour déterminer quand augmenter ou réduire la capacité. De nombreuses plateformes cloud proposent une scalabilité automatique basée sur des seuils de performance.
13. Automatisation de la surveillance des performances
13.1 SQL Server Emplois d'agent
Automatisez la collecte de données à l'aide de SQL Server Tâches d'agent pour une surveillance cohérente sans intervention manuelle.
Collecte de données programmée
- Dans SSMS, développez SQL Server Agent
- Faites un clic droit Emplois et sélectionnez New Job
- Nommez la tâche (par exemple, « Collecter les indicateurs de performance »)
- Cliquez à nouveau sur Étapes et ajouter une nouvelle étape
- Définir le type sur Script Transact-SQL
- Entrez votre script de collecte de données
- Cliquez à nouveau sur Horaires et ajouter un planning
- Configurer la fréquence (par exemple, toutes les 5 minutes)
- Cliquez à nouveau sur OK pour créer l'emploi
Rapports automatisés
Créez des tâches qui génèrent et envoient par courrier électronique des rapports de performances :
- Créer une procédure stockée qui génère des rapports
- Utilisez Database Mail pour envoyer des rapports par e-mail
- Planifiez la tâche pour qu'elle s'exécute quotidiennement ou hebdomadairement
13.2 Automatisation PowerShell
PowerShell fournit de puissantes capacités d’automatisation pour SQL Server moniteur de performances.
Scripts de collecte de compteurs de performances
$counters = @(
'\Processor(_Total)\% Processor Time',
'\Memory\Available MBytes',
'\PhysicalDisk(_Total)\Avg. Disk sec/Read'
)
$data = Get-Counter -Counter $counters -ComputerName 'SQLServer01'
$data.CounterSamples | Export-Csv 'C:\PerfLogs\counters.csv' -Append
Requêtes WMI
Utilisez WMI pour collecter des données de performances à partir de serveurs distants :
$cpu = Get-WmiObject Win32_Processor -ComputerName 'SQLServer01' $memory = Get-WmiObject Win32_OperatingSystem -ComputerName 'SQLServer01' Write-Host "CPU Usage: $($cpu.LoadPercentage)%" Write-Host "Available Memory: $([math]::Round($memory.FreePhysicalMemory/1MB,2)) GB"
Alerte automatisée
Créez des scripts PowerShell qui vérifient les métriques et envoient des alertes lorsque les seuils sont dépassés :
$cpuThreshold = 80
$cpu = (Get-Counter '\Processor(_Total)\% Processor Time').CounterSamples.CookedValue
if ($cpu -gt $cpuThreshold) {
Send-MailMessage -To 'dba@company.com' -Subject 'High CPU Alert' `
-Body "CPU usage is $cpu%" -SmtpServer 'smtp.company.com'
}
13.3 Création de tableaux de bord de surveillance
Visualisez les données de performance avec des tableaux de bord interactifs pour de meilleures informations.
Intégration Power BI
- Connectez Power BI à vos tables de données de performances
- Créer des visualisations pour les indicateurs clés
- Ajouter des slicers pour la plage horaire et la sélection du serveur
- Publier des tableaux de bord sur le service Power BI
- Configurer des programmes d'actualisation automatique
Création de tableaux de bord en temps réel
Utilisez des outils comme Grafana ou des applications Web personnalisées pour créer des tableaux de bord en temps réel qui interrogent directement les DMV et les compteurs de performances.
Visualisation des tendances historiques
Créez des graphiques linéaires montrant les tendances au fil du temps pour :
- Utilisation de l'UC
- Utilisation de la mémoire
- E / S disque
- Performances des requêtes
- Nombre de connexions
14. Études de cas et exemples pratiques
14.1 Étude de cas : Résoudre la pression de la mémoire
Identification des symptômes
Une fabrication SQL Server Les temps de réponse aux requêtes étaient lents aux heures de pointe. Les utilisateurs se plaignaient de dépassements de délai d'application et d'une dégradation des performances.
Contre-analyse
Les données du Performance Monitor ont révélé :
- L'espérance de vie des pages est réduite à 50 secondes (normale : > 300)
- Le taux de réussite du cache tampon est tombé à 85 % (normal : > 99 %)
- Les subventions de mémoire en attente affichaient fréquemment des valeurs de 5 à 10
- Les lectures de disques physiques par seconde ont augmenté de manière significative
Étapes de résolution
- à carreaux SQL Server paramètre de mémoire maximale – j'ai découvert qu'il était défini par défaut (illimité)
- Comparaison de la mémoire totale du serveur et de la mémoire totale du serveur Tarobtenir la mémoire du serveur – a montré un écart important
- Mémoire maximale du serveur configurée pour laisser 8 Go pour le système d'exploitation
- Activation de l'autorisation « Verrouiller les pages en mémoire » pour SQL Server compte de service
- Ajout de 32 Go de RAM supplémentaire au serveur
- Performances surveillées pendant une semaine – Espérance de vie des pages stabilisée au-dessus de 500 secondes
Résultat: Les temps de réponse aux requêtes se sont améliorés de 60 %, les plaintes des utilisateurs ont cessé et les performances des applications sont revenues à la normale.
14.2 Étude de cas : Optimisation des performances du processeur
Identification des symptômes
A SQL Server a constamment montré une utilisation du processeur supérieure à 90 % pendant les heures ouvrables, ce qui a entraîné un ralentissement des performances des applications et une frustration des utilisateurs.
Contre-analyse
Le suivi des performances a révélé :
- % Temps processeur moyen de 92 % avec des pics fréquents à 100 %
- Longueur de la file d'attente du processeur systématiquement supérieure à 4 (le serveur avait 8 cœurs)
- Les compilations SQL/s représentaient 25 % des requêtes par lots/s (elles devraient être inférieures à 10 %)
- Les recompilations SQL/s représentaient 15 % des requêtes par lots/s
Étapes de résolution
- Utilisé les DMV pour identifier les requêtes les plus consommatrices de CPU
- Plans d'exécution analysés pour les requêtes identifiées
- Découverte de plusieurs analyses de table sur de grandes tables en raison d'index manquants
- Création d'index appropriés basés sur les recommandations du plan d'exécution
- SQL dynamique identifié provoquant des compilations excessives
- Code d'application modifié pour utiliser des requêtes paramétrées
- Guide de planification mis en œuvre pour les procédures stockées problématiques
- Statistiques mises à jour sur les tables très utilisées
Résultat: L'utilisation du processeur a chuté à 45 % en moyenne pendant les heures ouvrables. Les temps d'exécution des requêtes ont été améliorés de 70 %. La réactivité des applications a été considérablement améliorée.
14.3 Étude de cas : Résolution du goulot d'étranglement des E/S de disque
Identification des symptômes
Les utilisateurs ont signalé une réponse extrêmement lente de l'application lors des opérations de chargement des données et du traitement par lots en soirée.
Contre-analyse
Les données de performance ont montré :
- La durée moyenne d'écriture sur le disque a dépassé 45 ms sur le lecteur du journal des transactions.
- Longueur moyenne de la file d'attente du disque : 12 sur le lecteur de fichiers de données
- Le % de temps disque est resté supérieur à 95 % pendant des heures lors des tâches par lots
- Le nombre d'écritures de pages par seconde était exceptionnellement élevé
Étapes de résolution
- Les paramètres de mémoire vérifiés étaient appropriés – aucun problème de mémoire n'a été détecté
- Configuration du disque analysée – tous les fichiers ont été découverts sur le même ensemble de broches
- Journaux de transactions séparés sur des disques SSD rapides dédiés
- Déplacement de tempdb vers des disques SSD séparés
- Implémentation de plusieurs fichiers de données tempdb (un par cœur)
- Mise à niveau des lecteurs de fichiers de données vers la configuration SSD RAID 10
- Tâches par lots optimisées pour utiliser des lots de transactions plus petits
- Ajout d'index pour réduire les analyses de table inutiles lors des opérations par lots
Résultat: Le temps moyen d'écriture sur disque est tombé à 3 ms. La longueur moyenne de la file d'attente sur disque est inférieure à 1. Le temps d'exécution des tâches par lots a été réduit de 75 %.
15. Tendances futures en SQL Server Le Monitoring
15.1 Intégration de l'IA et de l'apprentissage automatique
L'intelligence artificielle et l'apprentissage automatique transforment SQL Server moniteur de performances.
Analyses prédictives
Les modèles d'apprentissage automatique prédisent les besoins futurs en ressources à partir de données historiques. Ces systèmes peuvent prévoir :
- Quand la capacité de stockage sera épuisée
- Besoins attendus en CPU et en mémoire pendant les périodes de pointe
- Dégradation des performances des requêtes avant qu'elle n'affecte les utilisateurs
- Moments optimaux pour les opérations de maintenance
Détection d’Anomalies
Les outils d'IA détectent automatiquement les tendances inhabituelles dans les indicateurs de performance. Ils identifient les anomalies que les administrateurs humains pourraient manquer et distinguent les variations normales des problèmes réels.
Correction automatisée
Les systèmes d'auto-réparation résolvent automatiquement les problèmes courants lorsqu'ils sont détectés :
- Restarles services qui ont été arrêtés
- Réaffecter les ressources pendant les pics de charge
- Appliquer des correctifs pour les problèmes connus
- Reconstruire automatiquement les index fragmentés
15.2 Évolution de la surveillance basée sur le cloud
La surveillance du cloud continue d’évoluer avec de nouvelles fonctionnalités.
Plateformes de surveillance unifiées
Les plateformes modernes offrent une visibilité unique sur :
- Sur place SQL Server cas
- Nuage-hostbases de données ed
- Environnements hybrides
- La performance des applications
- Mesures d'infrastructure
Tendances d'observabilité
Le passage de la surveillance à l’observabilité met l’accent sur :
- Comprendre le comportement du système à partir des sorties
- Corrélation des métriques, des journaux et des traces
- Des connaissances approfondies sur les systèmes distribués
- Diagnostic des problèmes en temps réel
15.3 Systèmes de bases de données auto-réparateurs
A venir SQL Server les versions incluront davantage de capacités autonomes.
Optimisation automatique
Les bases de données s’optimiseront continuellement en :
- Création et suppression automatiques d'index en fonction de la charge de travail
- Réglage des paramètres de configuration pour des performances optimales
- Réécrire les requêtes inefficaces de manière transparente
- Gérer l'allocation des ressources de manière dynamique
Réglage intelligent
Les systèmes avancés apprendront des modèles de performances et appliqueront automatiquement les recommandations de réglage, réduisant ainsi le besoin d'intervention manuelle de l'administrateur de base de données.
16. Conclusion et points clés à retenir
16.1 Résumé des pratiques essentielles de surveillance
Efficace à partir de SQL Server Le suivi des performances nécessite une approche globale combinant outils, techniques et meilleures pratiques.
Récapitulatif des compteurs critiques
Concentrez les efforts de surveillance sur ces compteurs essentiels :
- Mémoire : durée de vie des pages, taux de réussite du cache tampon, allocations de mémoire en attente
- CPU : % de temps processeur, longueur de la file d'attente du processeur
- Disque : Durée moyenne du disque en secondes (lecture et écriture), longueur de la file d'attente du disque
- SQL Server: Requêtes par lots/s, Compilations/s, Connexions utilisateur
Résumé des meilleures pratiques
- Établir des lignes de base pendant les opérations normales
- Définir des seuils d'alerte intelligents basés sur des lignes de base
- Examiner régulièrement les données de performance
- Surcharge de surveillance de l'équilibre avec granularité des données
- Conserver les données à long terme pour l'analyse des tendances
- Utiliser des outils appropriés pour chaque scénario de surveillance
16.2 Approche d'amélioration continue
SQL Server Le suivi des performances n’est pas une activité ponctuelle mais un processus continu nécessitant un perfectionnement continu.
Cycles d'examen réguliers
- Quotidien : Consultez les alertes et les performances actuelles
- Hebdomadaire : Examiner les tendances et identifier les problèmes émergents
- Mensuel : Analyser les tendances à long terme et les besoins en capacité
- Trimestriel : Mettre à jour les données de référence et examiner l'efficacité du suivi
Rester à jour avec les outils
Maintenir à jour les outils et techniques de surveillance :
- Évaluer les nouvelles fonctionnalités de surveillance dans SQL Server mises à jour
- Tester les outils tiers émergents
- Participer à des formations et des conférences
- Prenez part à SQL Server Forums communautaires
- Partager les connaissances avec les membres de l'équipe
16.3 prochaines étapes
Mettre en œuvre le SQL Server surveiller systématiquement les performances :
Feuille de route de mise en œuvre
- Semaine 1 : Configurer le moniteur de performances avec les compteurs essentiels
- Semaine 2 : Créer des ensembles de collecteurs de données pour la collecte automatisée
- Semaine 3 : Établir des lignes de base pendant les opérations normales
- Semaine 4 : Configurer des alertes pour les seuils critiques
- Mois 2: Mettre en œuvre des outils de surveillance supplémentaires (DMV, événements étendus)
- Mois 3: Développer des tableaux de bord et des rapports personnalisés
- En cours: Affiner la surveillance en fonction de l'expérience et de l'évolution des besoins
Ressources supplémentaires
Continuez à vous renseigner sur SQL Server Surveillez les performances grâce à la documentation Microsoft, aux blogs communautaires et aux exercices pratiques. Testez différents outils et techniques pour trouver la solution la plus adaptée à votre environnement.
17. Foire aux questions (FAQ)
17.1 Quels sont les most important SQL Server compteurs de performance à surveiller ?
Le most critique SQL Server les compteurs de performance incluent :
- Mémoire : espérance de vie des pages (doit être > 300 secondes) et taux de réussite du cache tampon (doit être > 99 %)
- CPU : % de temps processeur (valeurs soutenues < 75 %) et longueur de la file d'attente du processeur (doit être < 2 par cœur)
- Disque : Durée moyenne de lecture et d'écriture (< 10 à 20 ms) et longueur de la file d'attente du disque (< 2 par disque)
- SQL Server: Requêtes par lots/s, compilations SQL/s et allocations de mémoire en attente (doit être 0)
Ces compteurs fournissent un aperçu complet de l’état du système et aident à identifier rapidement les goulots d’étranglement.
17.2 À quelle fréquence dois-je collecter des données de performance ?
La fréquence de collecte dépend de vos objectifs de surveillance :
- Surveillance de base : toutes les 1 minute (60 secondes)
- Dépannage actif : toutes les 15 à 30 secondes pendant de courtes périodes
- Tendance à long terme : toutes les 5 minutes
Évitez d'effectuer des collectes à haute fréquence en continu, car cela peut impacter les performances et générer un volume de données excessif. Privilégiez des intervalles plus longs pour la surveillance de routine et des intervalles plus courts uniquement pour l'analyse de problèmes spécifiques.
17.3 Quelle est la différence entre Performance Monitor et SQL Server Profileur ?
Moniteur de performances et SQL Server Les profileurs servent à différentes fins :
Analyseur de performances:
- Surveille le système et SQL Server compteurs de performance
- Suivi de l'utilisation des ressources (CPU, mémoire, disque)
- Faible surcharge, adapté à la surveillance continue
- Fournit des mesures globales au fil du temps
SQL Server Profileur :
- Traces individuelles SQL Server événements et requêtes
- Capture des informations détaillées sur l'exécution des requêtes
- Frais généraux plus élevés, non recommandé pour une utilisation continue
- Idéal pour résoudre des problèmes de requête spécifiques
- Déconseillé au profit des événements étendus
Utilisez Performance Monitor pour la surveillance globale du système et Extended Events (pas Profiler) pour une analyse détaillée au niveau des requêtes.
17.4 L'impact du moniteur de performances peut-il SQL Server performance?
Lorsqu'il est configuré correctement, Performance Monitor a un impact minimal sur SQL Server Performances, généralement inférieures à 2 %. Cependant, une surveillance excessive peut entraîner des problèmes :
- Trop de compteurs augmentent les frais généraux
- Des intervalles d'échantillonnage très courts (moins de 15 secondes) mettent à rude épreuve les ressources
- La collecte continue à haute fréquence génère des fichiers journaux volumineux
Pour minimiser l’impact :
- Surveiller uniquement les compteurs nécessaires
- Utiliser des intervalles d’échantillonnage appropriés (60 secondes pour la surveillance de routine)
- Stocker les journaux sur des lecteurs séparés des fichiers de base de données
- Planifiez une surveillance gourmande en ressources pendant les heures creuses
17.5 Combien de temps dois-je conserver les données de surveillance des performances ?
La conservation dépend de vos besoins d'analyse et de votre capacité de stockage :
- Minimum: 3 mois pour résoudre les problèmes récents
- Recommandée: 1 à 2 ans pour la planification des capacités et l'analyse des tendances
- Optimal : Indéfiniment si le stockage le permet, car les données historiques deviennent plus précieuses au fil du temps
Les données des compteurs de performance se compressent bien et occupent relativement peu d'espace. Envisagez d'archiver les données anciennes sur un espace de stockage distinct plutôt que de les supprimer. De nombreuses organisations constatent que des années de données historiques sont précieuses pour la planification de la capacité et l'identification des tendances à long terme.
17.6 Quelles sont les bonnes valeurs de seuil pour les compteurs de performances clés ?
Valeurs seuils recommandées pour l'alerte :
- Subventions de mémoire en attente : alerte lorsque > 0
- Durée de vie de la page : alerte lorsque < 300 secondes
- % Temps processeur : alerte lorsque > 80 % pendant 5 minutes
- Longueur de la file d'attente du processeur : alerte lorsque > 2 par cœur
- Moy. Disque sec/Lecture ou écriture : Alerte lorsque > 20 ms
- Longueur de la file d'attente du disque : alerte lorsque > 2 par disque
- Processus bloqués : alerte lorsque > 5
Ajustez ces seuils en fonction de vos données de référence et des caractéristiques spécifiques de votre charge de travail. Ce qui est normal dans un environnement peut indiquer des problèmes dans un autre.
17.7 Comment puis-je surveiller SQL Server performance à distance ?
Télécommande du moniteur SQL Server instances utilisant ces méthodes :
- Analyseur de performances: Spécifiez le nom de l'ordinateur distant lors de l'ajout de compteurs
- PowerShell : Utilisez le paramètre -ComputerName avec Get-Counter
- DMV : Connectez-vous à des serveurs distants via SSMS et interrogez les DMV
- Outils tiers : Most les outils de surveillance prennent en charge la surveillance des serveurs à distance
Assurez-vous que les règles de pare-feu autorisent le trafic de l'Analyseur de performances et que vous disposez des autorisations appropriées sur le serveur distant. Pour plusieurs serveurs, envisagez de mettre en place une surveillance centralisée avec un serveur et une base de données dédiés.
17.8 Quel est le meilleur outil gratuit pour SQL Server moniteur de performances ?
Plusieurs excellents outils gratuits sont disponibles pour la surveillance SQL Server performance:
- Moniteur de performances Windows : Intégré, complet et fiable
- Moniteur d'activité SSMS : Surveillance en temps réel sans installation supplémentaire
- Événements prolongés : Surveillance légère des événements intégrée SQL Server
- sp_WhoIsActive : Procédure stockée gratuite populaire pour une surveillance détaillée des activités
- Tableau de bord DBA : Outil de surveillance open source avec des fonctionnalités complètes
- SQLWATCH : Open source avec des capacités de surveillance en temps quasi réel
Formeost organisations, Performance Monitor combiné aux outils SSMS et sp_WhoIsActive offre d'excellentes capacités de surveillance sans c supplémentaireost.
17.9 Comment exporter les données PerfMon pour analyse ?
Exportez les données du moniteur de performances à l’aide de ces méthodes :
Exporter au format CSV :
- Ouvrez le Moniteur de performances avec votre fichier journal chargé
- Cliquez avec le bouton droit sur le graphique et sélectionnez Enregistrer les données sous
- Choisissez Fichier texte (délimité par des virgules) (.csv)
- Sélectionnez l'emplacement et enregistrez
- Ouvrir dans Excel pour analyse
Utiliser la commande Relog :
relog input.blg -f csv -o output.csv
Cet utilitaire de ligne de commande convertit les fichiers journaux binaires (.blg) au format CSV pour une analyse plus facile dans les applications de feuille de calcul.
17.10 Quand dois-je utiliser des outils de surveillance tiers au lieu des options intégrées ?
Envisagez des outils tiers lorsque :
- Gérer un grand nombre de SQL Server instances (10+)
- Nécessitant une surveillance centralisée sur plusieurs centres de données
- Besoin de fonctionnalités avancées telles que l'analyse prédictive ou la détection d'anomalies
- Souhaitant des alertes intégrées aux systèmes de gestion des incidents
- Exiger des rapports de conformité et une analyse historique
- Manque de ressources DBA pour créer et maintenir des solutions personnalisées
- Surveillance d'environnements de bases de données hétérogènes (SQL Server, Oracle, MySQL, etc.)
Les outils intégrés sont particulièrement adaptés aux environnements de petite taille ou aux administrateurs de bases de données expérimentés capables de développer des solutions de surveillance personnalisées. Les outils tiers offrent un gain de temps considérable, des fonctionnalités avancées et un support professionnel.
18. Ressources supplémentaires
18.1 Documentation officielle
Microsoft fournit une documentation complète pour SQL Server moniteur de performances :
- SQL Server Documentation du moniteur de performances : https://learn.microsoft.com/en-us/sql/relational-databases/performance-monitor/
- Vues de gestion dynamique : https://learn.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/
- Événements prolongés : https://learn.microsoft.com/en-us/sql/relational-databases/extended-events/
- Magasin de requêtes : https://learn.microsoft.com/en-us/sql/relational-databases/performance/monitoring-performance-by-using-the-query-store
- Réglage et surveillance des performances : https://learn.microsoft.com/en-us/sql/relational-databases/performance/
18.2 Outils et téléchargements recommandés
Des outils indispensables pour SQL Server moniteur de performances :
- Outil PAL : https://github.com/clinthuffman/PAL
- sp_WhoIsActive : http://whoisactive.com/
- Tableau de bord DBA : https://dbadash.com/
- SQLWATCH : https://github.com/marcingminski/sqlwatch
- Kit de premier intervenant (Brent Ozar) : https://www.brentozar.com/first-aid/
- SQL Server Atelier de gestion : https://learn.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
18.3 Ressources communautaires
Apprenez de la SQL Server communauté:
- SQL Server Centrale: https://www.sqlservercentral.com/
- Blog de Brent Ozar : https://www.brentozar.com/blog/
- Cabane SQL : https://www.sqlshack.com/
- Conseils MSSQL : https://www.mssqltips.com/
- Reddit r/SQLServer : https://www.reddit.com/r/SQLServer/
- Stack Overflow SQL Server tag: https://stackoverflow.com/questions/tagged/sql-server
Ces ressources fournissent des tutoriels, des conseils de dépannage et les meilleures pratiques d'experts expérimentés. SQL Server Professionnels. Participer aux forums communautaires vous permet d'apprendre des expériences des autres et de partager vos propres connaissances.
À propos de l’auteur
Yuan Sheng est un administrateur de base de données senior (DBA) avec plus de 10 ans d'expérience dans SQL Server Environnements et gestion de bases de données d'entreprise. Il a résolu avec succès des centaines de scénarios de récupération de bases de données dans des organisations du secteur financier, de la santé et de l'industrie manufacturière.
Yuan se spécialise dans SQL Server récupération de base de données, solutions à haute disponibilitéet l'optimisation des performances. Son expérience pratique approfondie comprend la gestion de bases de données multi-téraoctets et la mise en œuvre Groupes de disponibilité toujours activéset en développant des stratégies automatisées de sauvegarde et de restauration pour les systèmes d'information critiques de l'entreprise.
Grâce à son expertise technique et à son approche pratique, Yuan se concentre sur la création de guides complets qui aident les administrateurs de bases de données et les professionnels de l'informatique à résoudre des problèmes complexes. SQL Server défis efficacement. Il se tient au courant des dernières SQL Server les versions et les technologies de base de données en constante évolution de Microsoft, testant régulièrement des scénarios de récupération pour garantir que ses recommandations reflètent les meilleures pratiques du monde réel.
Vous avez des questions sur SQL Server Besoin d'aide pour la récupération de votre base de données ? Yuan vous accueille. commentaires et suggestions pour améliorer ces ressources techniques.