บทความต่อไปนี้อธิบายความแตกต่างที่สำคัญระหว่างตารางฮีปและตารางคลัสเตอร์
ในขณะที่ทำงานกับตารางใน SQL Serverผู้ใช้มักเผชิญกับภาวะที่กลืนไม่เข้าคายไม่ออกในการใช้ตารางแบบคลัสเตอร์หรือตารางฮีป ตารางที่ไม่มีดัชนีแบบคลัสเตอร์เรียกว่า Heap Tables และตารางที่มีดัชนีแบบคลัสเตอร์เรียกว่า Clustered Tables โดยทั่วไปดัชนีแบบคลัสเตอร์จะจัดลำดับวิธีการจัดเก็บบันทึกทางกายภาพในตารางใหม่ หน้าข้อมูลมีอยู่ในโหนดปลายสุดของดัชนีแบบคลัสเตอร์
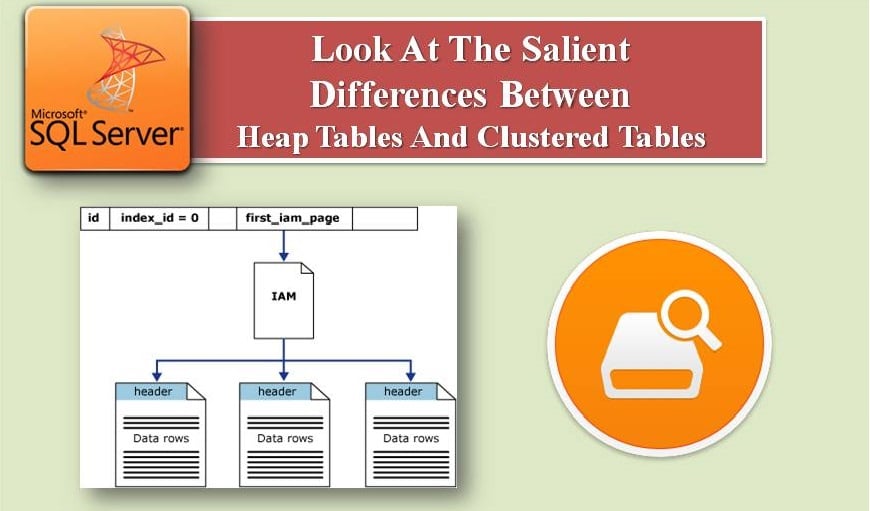
บทความนี้จะกล่าวถึงตารางทั้งสองประเภทนี้โดยละเอียดยิ่งขึ้น
ตารางคลัสเตอร์และฮีป
ตารางแบบคลัสเตอร์ให้ประโยชน์แก่ผู้ใช้มากกว่าตารางฮีป เนื่องจากช่วยให้ผู้ใช้ใช้ดัชนีในการค้นหาแถวได้เร็วกว่าตารางฮีป และจัดเก็บข้อมูล/บันทึกทางกายภาพโดยการสร้างดัชนีคลัสเตอร์ขึ้นใหม่
ข้อมูลทางกายภาพของคุณอาจกระจัดกระจายหากมีกิจกรรม INSERT, DELETE และ UPDATE มากกว่าตารางในข้อมูลของคุณ เป็นที่ทราบกันดีว่าข้อมูลที่กระจัดกระจายสามารถเพิ่มลงในพื้นที่ที่สิ้นเปลืองและไม่พึงประสงค์ได้ เนื่องจากหากคุณเรียกใช้แบบสอบถาม จะต้องอ่านหน้าเพิ่มเติมอีกหลายหน้า เนื่องจากขณะนี้มีหน้าเต็มบางส่วนมากขึ้น เรามาดูวิธีแก้ปัญหาการกระจายตัวของข้อมูลกันดีกว่า
ความแตกต่างระหว่างฮีปและตารางคลัสเตอร์
ปัญหาการแยกส่วนสามารถแก้ไขได้โดยการพิจารณาความจำเป็นที่จะต้องมีดัชนีแบบคลัสเตอร์ในตารางของคุณหรือไม่ ท้ายที่สุดแล้ว มันเป็นดัชนีแบบคลัสเตอร์หรือฮีปที่ควบคุมการจัดเก็บข้อมูลทางกายภาพของตารางของคุณ ตารางใดๆ ในฐานข้อมูลของคุณสามารถมีดัชนีได้เพียงประเภทเดียวเท่านั้น ในการตัดสินใจเลือกเราต้องเข้าใจความแตกต่างพื้นฐานระหว่างสองสิ่งนี้ซึ่งมีดังต่อไปนี้
- ในฮีปไม่มีลำดับในการจัดเก็บข้อมูล แต่ในคลัสเตอร์การจัดเก็บข้อมูลมีลำดับขึ้นอยู่กับคีย์ดัชนีของคลัสเตอร์
- หน้าข้อมูลไม่ได้เชื่อมโยงใน Heap ในขณะที่ในตารางแบบคลัสเตอร์จะมีการเชื่อมโยงและมีการเข้าถึงตามลำดับที่เร็วกว่า
- ฮีปมีค่าดัชนี 0 และคลัสเตอร์มีค่าดัชนี 1 สำหรับมุมมองแค็ตตาล็อก sys.indexes
- Clustered Index ดึงข้อมูลได้เร็วกว่าตารางฮีปเนื่องจากมีคีย์ Clustered Index
fragmentation
จากความแตกต่างระหว่าง Clustered และ Heap Tables เราสามารถแก้ไขปัญหาการกระจายตัวได้ การกระจายตัวเกิดขึ้นเนื่องจากการใช้กิจกรรม INSERT, DELETE และ UPDATE อย่างไรก็ตาม หากคุณมี Heap Table และมีเฉพาะกิจกรรม INSERT การกระจายตัวจะไม่เกิดขึ้น หากคุณใช้คีย์ดัชนีตามลำดับ (ค่าข้อมูลประจำตัว) และมีเพียง INSERTS ดัชนีคลัสเตอร์ของคุณจะไม่ถูกแยกส่วน แต่ถ้าคุณใช้ INSERTS หรือ DELETES จำนวนมาก ตารางจะกระจัดกระจาย
ดังนั้นจึงแนะนำให้ใช้ Clustered Index เนื่องจากขึ้นอยู่กับคีย์ Index และใช้พื้นที่น้อยกว่า สามารถเขียนบันทึกใหม่ลงในเพจที่มีอยู่แล้วในพื้นที่ว่างที่มีอยู่ได้
หากต้องการพิจารณาการใช้ฮีปหรือตารางคลัสเตอร์ คุณยังสามารถลองใช้ DBCC SHOWCONTIG หรือ DMV ใหม่ได้ เนื่องจากทั้งสองคำสั่งนี้สามารถให้ข้อมูลเชิงลึกเกี่ยวกับปัญหาการกระจายตัวในตารางของคุณได้ ในตารางแบบคลัสเตอร์ การกระจายตัวสามารถแก้ไขได้โดยการจัดระเบียบใหม่หรือสร้างดัชนีคลัสเตอร์ของคุณใหม่
การลงทุนในก SQL Server ซ่อมแซม เครื่องมือนี้เป็นสิ่งจำเป็นสำหรับบริษัทที่ใช้ MS SQL Server ฐานข้อมูลบนเซิร์ฟเวอร์ที่ใช้งานจริง ในความเป็นจริงมันสามารถพิสูจน์ได้ว่าเป็นผู้ช่วยชีวิตในกรณีที่ฐานข้อมูลล่ม
บทนำผู้เขียน:
Victor Simon เป็นผู้เชี่ยวชาญด้านการกู้คืนข้อมูลใน DataNumen, Inc. ซึ่งเป็นผู้นำระดับโลกด้านเทคโนโลยีการกู้คืนข้อมูล ได้แก่ ซ่อม mdb และผลิตภัณฑ์ซอฟต์แวร์กู้คืน sql ดูข้อมูลเพิ่มเติมได้ที่ https://www.datanumen.com/